Recently I came upon this little tidbit and initially thought how wonderful, (NMT is surely rising!) and decided to take a closer look and read through the research paper. This exercise left me a little uncertain as I now felt doubt, and began to suspect that this is just another example of that never-ending refrain of the MT world, the empty promise. Without a doubt Google had made some real progress, but “Nearly Indistinguishable From Human Translation” and “GNMT reduces translation errors by more than 55%-85% on several major language pairs “. Hmmm, not really, not really at all, was what my pesky brain kept telling me, especially as I saw this announcement coming up again and again through many news channels, probably pushed heavily by the Google marketing infrastructure.
Surely the great Google of the original “Don’t Be Evil” ethos would not bullshit us thus. (In their 2004 founders' letter prior to their initial public offering, Larry Page and Sergey Brin explained that their "Don't be evil" culture prohibited conflicts of interest, and required objectivity and an absence of bias.) Apparently, Gizmodo already knew about the broken promise in 2012. My friend Roy told me that: Following Google's corporate restructuring under the conglomerate Alphabet Inc. in October 2015, the slogan was replaced in the Alphabet corporate code of conduct by the phrase "Do the right thing". However, to this day, the Google code of conduct still contains the phrase "Don't be evil”. This ability to conveniently bend the rules (but not break the law) and make slippery judgment calls which are convenient to corporate interests, is well described by Margaret Hodge in this little snippet. Clearly, Google knows how to push self-congratulating, mildly false content through the global news gathering and distribution system by using terms like research and breakthrough with somewhat shaky research data that includes math, sexy flowcharts, and many tables showing “important research data”. They are after all the kings of SEO. However, I digress.
The basic deception I speak of, and yes I do understand that those might be strong words, is the overstatement of the actual results, using questionable methodology, in what I would consider an arithmetical manipulation of the basic data, to support corporate marketing messaging spin (essentially to bullshit the casual, trusting, but naïve reader who is not aware of the shaky foundations at play here and of statistics in general). Not really a huge crime, but surely just a little bit evil and sleazy. Not quite the Wells Fargo, Monsanto, Goldman Sachs and Valiant & Turing Pharmaceuticals (medical drug price gouging) level of evil and sleazy but give them time and I am sure they could rise to this level, and they quite possibly will step up their sleaze game if enough $$$s and business advantage issues are at stake. AI and machine learning can be used for all kinds of purposes both sleazy or not as long as you have the right power and backing.
So basically I see three problems with this announcement:
 Take a look at the bar chart they provide below and tell me if any of the bars looks like there was a “55% to 85%” improvement from the blue line (PBMT) to the top of the green line (GNMT). Do the green chunks look like they could possibly be 55% or more of the blue chunk? I surely don’t see it until I put my Google glasses on.
Take a look at the bar chart they provide below and tell me if any of the bars looks like there was a “55% to 85%” improvement from the blue line (PBMT) to the top of the green line (GNMT). Do the green chunks look like they could possibly be 55% or more of the blue chunk? I surely don’t see it until I put my Google glasses on.

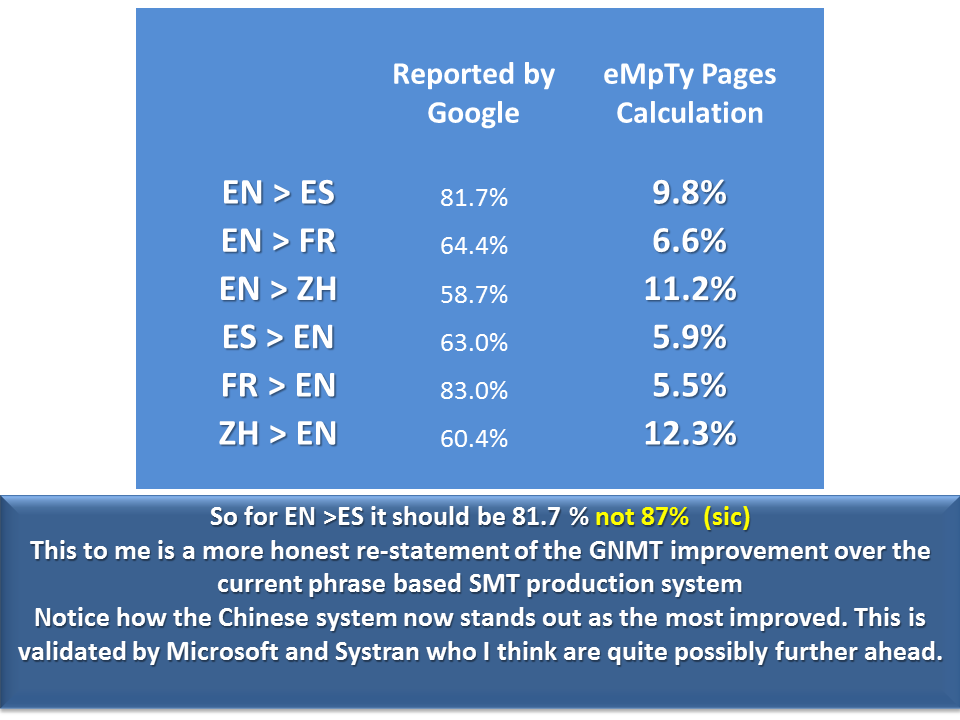
I think it is worth restating the original data in Table 10, in what to me is a much more forthright, accurate, reasonable, and less devious presentation shown below. Even though I remain deeply skeptical about the actual value of humans rating multiple translations of the same source sentence on a scale on 0 to 6. These restated results are also very positive so I am not sure why one would need to overstate these unless there was some marketing directive behind it. Also, these results point out that the English <> Chinese system experienced the biggest gains which both Microsoft and SYSTRAN have already confirmed and also possibly explains why it is the only GNMT system in production. For those who believe that Google is the first to do this, this is not so, both Facebook and Microsoft have production NMT systems running for some time now.
 When we look at how these systems are improving with the commonly used BLEU score metric, we see that the progress is much less striking. MT has been improving slowly and incrementally as you can see from the EN > FR system data that was provided below. To put this is some context, Systran had an average of 5 BLEU points improvement on their NMT systems over the previous generation V8 systems. Of course, not the same training/test data and technically not exactly equivalent for absolute comparison, but the increase is relative to their old production systems and is thus a hyperbole-free statement of progress.
When we look at how these systems are improving with the commonly used BLEU score metric, we see that the progress is much less striking. MT has been improving slowly and incrementally as you can see from the EN > FR system data that was provided below. To put this is some context, Systran had an average of 5 BLEU points improvement on their NMT systems over the previous generation V8 systems. Of course, not the same training/test data and technically not exactly equivalent for absolute comparison, but the increase is relative to their old production systems and is thus a hyperbole-free statement of progress.

 The Google research team uses human rating since BLEU is not always reliable and has many flaws and most of us in the MT community feel that competent human assessment is a way to keep it real. But this is what Google say about the human assessment result: “Note that we have observed that human raters, even though fluent in both languages, do not necessarily fully understand each randomly sampled sentence sufficiently and hence cannot necessarily generate the best possible translation or rate a given translation accurately.” They provide a table to show some samples of where they disagree. Would that not be a clue to suggest that the side-by-side comparison is flawed? So what does this mean? The human rating was not really competent? The raters don’t understand the machine’s intent and process? That this is a really ambiguous task so maybe the results are kind of suspect even though you have found a way to get a numerical representation of a really vague opinion? Or all of the above? Maybe you should not show humans multiple translations of the same thing and expect them to score them consistently and accurately.
The Google research team uses human rating since BLEU is not always reliable and has many flaws and most of us in the MT community feel that competent human assessment is a way to keep it real. But this is what Google say about the human assessment result: “Note that we have observed that human raters, even though fluent in both languages, do not necessarily fully understand each randomly sampled sentence sufficiently and hence cannot necessarily generate the best possible translation or rate a given translation accurately.” They provide a table to show some samples of where they disagree. Would that not be a clue to suggest that the side-by-side comparison is flawed? So what does this mean? The human rating was not really competent? The raters don’t understand the machine’s intent and process? That this is a really ambiguous task so maybe the results are kind of suspect even though you have found a way to get a numerical representation of a really vague opinion? Or all of the above? Maybe you should not show humans multiple translations of the same thing and expect them to score them consistently and accurately.
Could it be that they need a more reliable human assessment process and maybe they should call Juan Rowda and Silvio Picinini at eBay and ask them how to do this correctly or at least read their posts in this blog. Or maybe they can hire competent translators to guide this human evaluation and assessment process instead of assigning “human raters” a task that simply does not make sense, no matter how competent they are as translators.
In the grand scheme of things, the transgressions and claims made in this Google announcement are probably a minor deception but I still think they should be challenged and exposed if possible, and if it is actually fair criticism. We live in a world where corporate malfeasance has become the norm of the day. Here we have a small example which could build into something worse. Monsanto, Well Fargo, Goldman Sachs do not have evil people (maybe just at the top) but they have a culture that rewards certain kinds of ethically challenged behavior if it benefits the company or helps you “make your numbers”. To me, this is an example in-kind and tells you something about the culture at Google.
We are still quite a long way from “Nearly Indistinguishable From Human Translation”. We need to be careful about overstating the definite and clear progress that actually has been made in this case. For some reason, this (overstatement of progress) is something that happens over and over again in MT. Keep in mind that drawing such sweeping conclusions on a sample of 500 is risky with big data applications (probably 250 Million+ sentence pairs) even when the sample is really well chosen and the experiment has an impeccable protocol which in this case is SIMPLY NOT TRUE for the human evaluation. The rating process is flawed to such an extent that we have to question some or many of the conclusions drawn here.The most trustworthy data presented here are the BLEU scores assuming it is truly a blind test set and no Google glasses were used to peek into the test.
This sentence was just pointed out to me after this post went live, thus, I am adding an update as an in place postscript. Nature (Journal of Science) provides a little more detail on the human testing process.
These results are consistent with what SYSTRAN has reported (described here ), and actually are slightly less compelling at a BLEU score level than the results SYSTRAN has had as I explained above. (Yes Mike I know it is not the same training and test set.)
Now that I have gotten the rant off my chest, here are my thoughts on what this “breakthrough” might mean:
The marketing guy at Google who pushed this announcement in its current form should be asked to watch this video (NSFW link, do NOT click on it if you are easily offended) at least 108 times. The other guys should also watch it a few times too. Seriously, let’s not get carried away just yet. Let’s wait to hear from actual users and let’s wait to see how it works in production use scenarios before we celebrate.
As for the Google corporate motto, I think it has been already true for some time now that Google is at least slightly evil, and I recommend you watch the three-minute summary by Margaret Hodge to see what I mean. Sliding down a slippery slope is a lot easier than standing on a narrow steep ledge in high winds. In today's world, power and financial priorities rule over ethics, integrity and principal and Google is just following the herd that includes their friends at Well Fargo, Goldman Sachs, VW, and Monsanto. I said some time ago that a more appropriate motto for Google today might actually be: “You Give, We Take.” Sundar should walk around campus in a T-shirt (preferably one made by underpaid child labor in Bangladesh) with this new motto boldly emblazoned on it in some kind of a cool Google font. At least then Google marketing would not have to go through the pretense of having any kind of ethical, objective or non-biased core which the current (original) motto forces them to contend with repeatedly. The Vedic long view of the human condition across eons, says we are currently living in the tail end of the Kali Yuga, an age of darkness and falsehood and wrong values. An age when charlatans (Goldman Sachs, VW, Monsanto, Wells Fargo and Google) are revered and even considered prophets. Hopefully, this era ends soon.
Florian Faes has made a valiant effort to provide a fair and balanced view on these claims from a variety of MT expert voices. I particularly enjoyed the comments by Rico Sennrich of the University of Edinburgh who cuts through the Google bullshit most effectively. For those who think that my rant is unwarranted, I suggest that you read the Slator discussion, as you will get a much more diverse opinion. Florian even has rebuttal comments from Mike Schuster at Google whose responses sound more than a little bit like the spokespersons at Well Fargo, VW and Goldman Sachs to me. Also, for the record, I don’t buy the Google claim “Our system’s translation quality approaches or surpasses all currently published results,” unless you consider only their own results. I am willing to bet $5 that both Facebook and Microsoft (and possibly Systran and Baidu) have equal or better technology. Slator is the best thing that has happened to the “translation industry” in terms of relevant current news and investigative journalism and I hope that they will thrive and succeed.
I remain willing to stand corrected if my criticism is unfounded or unfair, especially if somebody from Google sets me straight. But I won’t hold my breath, not until the end of the Kali Yuga anyway.
PEACE.

Surely the great Google of the original “Don’t Be Evil” ethos would not bullshit us thus. (In their 2004 founders' letter prior to their initial public offering, Larry Page and Sergey Brin explained that their "Don't be evil" culture prohibited conflicts of interest, and required objectivity and an absence of bias.) Apparently, Gizmodo already knew about the broken promise in 2012. My friend Roy told me that: Following Google's corporate restructuring under the conglomerate Alphabet Inc. in October 2015, the slogan was replaced in the Alphabet corporate code of conduct by the phrase "Do the right thing". However, to this day, the Google code of conduct still contains the phrase "Don't be evil”. This ability to conveniently bend the rules (but not break the law) and make slippery judgment calls which are convenient to corporate interests, is well described by Margaret Hodge in this little snippet. Clearly, Google knows how to push self-congratulating, mildly false content through the global news gathering and distribution system by using terms like research and breakthrough with somewhat shaky research data that includes math, sexy flowcharts, and many tables showing “important research data”. They are after all the kings of SEO. However, I digress.
The basic deception I speak of, and yes I do understand that those might be strong words, is the overstatement of the actual results, using questionable methodology, in what I would consider an arithmetical manipulation of the basic data, to support corporate marketing messaging spin (essentially to bullshit the casual, trusting, but naïve reader who is not aware of the shaky foundations at play here and of statistics in general). Not really a huge crime, but surely just a little bit evil and sleazy. Not quite the Wells Fargo, Monsanto, Goldman Sachs and Valiant & Turing Pharmaceuticals (medical drug price gouging) level of evil and sleazy but give them time and I am sure they could rise to this level, and they quite possibly will step up their sleaze game if enough $$$s and business advantage issues are at stake. AI and machine learning can be used for all kinds of purposes both sleazy or not as long as you have the right power and backing.
So basically I see three problems with this announcement:
- Arithmetic manipulation to create the illusion of huge progress. (Like my use of font size and bold to make the word huge seem more important than it is.)
- Questionable human evaluation methodology which produces rating scores that are then further arithmetically manipulated and used to support the claims of “breakthrough” progress. Humans are unlikely to rate 3 different translations of the same thing on a scale of 0 to 6 (crap to perfect) accurately and objectively. Ask them to do it 500 times and they are quite likely to give you pretty strange and illogical results. Take a look at just four pages of this side-by-side comparison and see for yourself. The only case I am aware of where this kind of a translation quality rating was done with any reliability and care was by Appen Butler Hill for Microsoft. But translation raters there were not made to make a torturous comparison of several versions of the same translation, and then provide an independent rating for each. Humans do best (if reliable and meaningful deductions are sought from the exercise) when asked to compare two translations and asked a simple and clear question like: “Which one is better?” Interestingly even the Google team noted that: “We observed that human raters, even though fluent in both languages, do not necessarily fully understand each randomly sampled sentence sufficiently”. Yes, seriously dude, are you actually surprised? Methinks that possibly there is a kind of stupor that sets in when one spends too much time in the big data machine learning super-special room, that numbs the part of the brain where common sense resides.
- Then taking this somewhat shaky research and making the claim that the GNMT is “Nearly Indistinguishable From Human Translation” and figuring out a way to present this as “55% to 85%” improvements.
Marketing Deception = fn (small BLEU improvements, shaky human evaluation on a tiny amount of data that sort of support our claim, math formulas, very sexy multimedia flow chart, lots of tables and data to make it look like science, HUGE amount of hyperbole, SEO marketing so everybody publishes it, like it was actually a big breakthrough and meaningful research.)
Arithmetic Manipulation
So onto some specifics. Here is the table that provides the “breakthrough results” to make the over-the-top claims. They did not even bother to do the arithmetic correctly on the first row! Seriously, are they not allowed to use Excel or at least a calculator? :

I think it is worth restating the original data in Table 10, in what to me is a much more forthright, accurate, reasonable, and less devious presentation shown below. Even though I remain deeply skeptical about the actual value of humans rating multiple translations of the same source sentence on a scale on 0 to 6. These restated results are also very positive so I am not sure why one would need to overstate these unless there was some marketing directive behind it. Also, these results point out that the English <> Chinese system experienced the biggest gains which both Microsoft and SYSTRAN have already confirmed and also possibly explains why it is the only GNMT system in production. For those who believe that Google is the first to do this, this is not so, both Facebook and Microsoft have production NMT systems running for some time now.

The Questionable Human Side-by-Side Evaluation
I have shared several articles in this blog about the difficulties of doing human evaluations of MT output. It is especially hard when humans are asked to provide some kind of a (purportedly objective) score to a candidate translation. While it may be easier to rank multiple translations from best to worst (like they do in WMT16), the research shows that this is an area plagued with problems. Problems here means it is difficult to obtain results that are objective, consistent and repeatable. This also means that one should be very careful about drawing sweeping conclusions from such questionable side-by-side human evaluations. This is also shown by some of the Google research results as shown below which are counter-intuitive.
Could it be that they need a more reliable human assessment process and maybe they should call Juan Rowda and Silvio Picinini at eBay and ask them how to do this correctly or at least read their posts in this blog. Or maybe they can hire competent translators to guide this human evaluation and assessment process instead of assigning “human raters” a task that simply does not make sense, no matter how competent they are as translators.
In the grand scheme of things, the transgressions and claims made in this Google announcement are probably a minor deception but I still think they should be challenged and exposed if possible, and if it is actually fair criticism. We live in a world where corporate malfeasance has become the norm of the day. Here we have a small example which could build into something worse. Monsanto, Well Fargo, Goldman Sachs do not have evil people (maybe just at the top) but they have a culture that rewards certain kinds of ethically challenged behavior if it benefits the company or helps you “make your numbers”. To me, this is an example in-kind and tells you something about the culture at Google.
We are still quite a long way from “Nearly Indistinguishable From Human Translation”. We need to be careful about overstating the definite and clear progress that actually has been made in this case. For some reason, this (overstatement of progress) is something that happens over and over again in MT. Keep in mind that drawing such sweeping conclusions on a sample of 500 is risky with big data applications (probably 250 Million+ sentence pairs) even when the sample is really well chosen and the experiment has an impeccable protocol which in this case is SIMPLY NOT TRUE for the human evaluation. The rating process is flawed to such an extent that we have to question some or many of the conclusions drawn here.The most trustworthy data presented here are the BLEU scores assuming it is truly a blind test set and no Google glasses were used to peek into the test.
This sentence was just pointed out to me after this post went live, thus, I am adding an update as an in place postscript. Nature (Journal of Science) provides a little more detail on the human testing process.
"For some other language pairs, the accuracy of the NMTS approached that of human translators, although the authors caution that the significance of the test was limited by its sample of well-crafted, simple sentences."Would this not constitute academic fraud? So now we have them saying both that the "raters" did not understand the sentences and that the sentences were essentially made simple i.e. rigged. To get a desirable and publishable result? For most in the academic community this would be enough to give pause and reason to be very careful about making any claims, but of course not for Google who looks suspiciously like they did engineer "the results" at a research level.
These results are consistent with what SYSTRAN has reported (described here ), and actually are slightly less compelling at a BLEU score level than the results SYSTRAN has had as I explained above. (Yes Mike I know it is not the same training and test set.)
Now that I have gotten the rant off my chest, here are my thoughts on what this “breakthrough” might mean:
- NMT is definitely proving to be a way to drive MT quality upward and forward but for now, is limited to those with deep expertise and access to huge processing and data resources.
- NMT problems (training and inference speed, small vocabulary problem, missing words etc..) will be solved sooner rather than later.
- Experiment results like these should be interpreted with care, especially if they are based on such an ambiguous human rating score system. Don’t just read the headline and believe them, especially when they come from people with vested interests e.g. Google.
- Really good MT always looks like human translation, but what matters is how many segments in a set of 100,000 look like a human translation. We should save our "nearly indistinguishable" comments for when we get closer to 90% or at least 70% of all these segments being almost human.
- The success at Google, overstated though it is, has just raised the bar for both the Expert and especially the Moses DIY practitioners, which makes even less sense now since you could almost always do better with generic Google or Microsoft who also has NMT initiatives underway and in production.
- We now have several end-to-end NMT initiatives underway and close to release from Facebook, Microsoft, Google, Baidu, and Systran. For the short term, I still think that Adaptive MT is more meaningful and impactful to users in the professional translation industry, but as SYSTRAN has suggested, NMT "adapts" very quickly with very little effort with small volumes of human corrective input. This is a very important requirement for MT use in the professional world. If NMT is as responsive to corrective feedback as SYSTRAN is telling us, I think we are going to see a much faster transition to NMT.
The marketing guy at Google who pushed this announcement in its current form should be asked to watch this video (NSFW link, do NOT click on it if you are easily offended) at least 108 times. The other guys should also watch it a few times too. Seriously, let’s not get carried away just yet. Let’s wait to hear from actual users and let’s wait to see how it works in production use scenarios before we celebrate.
As for the Google corporate motto, I think it has been already true for some time now that Google is at least slightly evil, and I recommend you watch the three-minute summary by Margaret Hodge to see what I mean. Sliding down a slippery slope is a lot easier than standing on a narrow steep ledge in high winds. In today's world, power and financial priorities rule over ethics, integrity and principal and Google is just following the herd that includes their friends at Well Fargo, Goldman Sachs, VW, and Monsanto. I said some time ago that a more appropriate motto for Google today might actually be: “You Give, We Take.” Sundar should walk around campus in a T-shirt (preferably one made by underpaid child labor in Bangladesh) with this new motto boldly emblazoned on it in some kind of a cool Google font. At least then Google marketing would not have to go through the pretense of having any kind of ethical, objective or non-biased core which the current (original) motto forces them to contend with repeatedly. The Vedic long view of the human condition across eons, says we are currently living in the tail end of the Kali Yuga, an age of darkness and falsehood and wrong values. An age when charlatans (Goldman Sachs, VW, Monsanto, Wells Fargo and Google) are revered and even considered prophets. Hopefully, this era ends soon.
Florian Faes has made a valiant effort to provide a fair and balanced view on these claims from a variety of MT expert voices. I particularly enjoyed the comments by Rico Sennrich of the University of Edinburgh who cuts through the Google bullshit most effectively. For those who think that my rant is unwarranted, I suggest that you read the Slator discussion, as you will get a much more diverse opinion. Florian even has rebuttal comments from Mike Schuster at Google whose responses sound more than a little bit like the spokespersons at Well Fargo, VW and Goldman Sachs to me. Also, for the record, I don’t buy the Google claim “Our system’s translation quality approaches or surpasses all currently published results,” unless you consider only their own results. I am willing to bet $5 that both Facebook and Microsoft (and possibly Systran and Baidu) have equal or better technology. Slator is the best thing that has happened to the “translation industry” in terms of relevant current news and investigative journalism and I hope that they will thrive and succeed.
I remain willing to stand corrected if my criticism is unfounded or unfair, especially if somebody from Google sets me straight. But I won’t hold my breath, not until the end of the Kali Yuga anyway.
PEACE.

Good wrap-up, Kirti. I agree that NMT is not only on its way, but it's here for some of Google's languages. We can measure the improvements over the coming months/years. I think the big breakthrough in Google's announcement is not the quality, but rather their ability to generate and operate NMT engines in a Big Data cloud environment.
ReplyDeleteRe quality, GT's improvement claims are understandable when we examined under the perspective of Google's baseline. Memsource recently published a groundbreaking report: http://blog.memsource.com/machine-vs-human-translation/ . We've had 10 years of Big Data cloud SMT refinements. This report covers 38 million words in a production environment, not a simulated research environment. It's a first and reveals that 90% or more of the suggestions from these engines (GT and Microsoft) under control of a professional post-editors are not good enough to publish without change for 23 of 25 language pairs.
An earlier NMT report cited a 26% improvement over phrase-based SMT. Layering 26% on top of 10% baseline is boring. I don't know if Google engaged in marketing deception with this report, but clearly, any improvements attributed to NMT is understandably hype-worthy in this "translation as a utility" (TaaU) environment.
Out of the TaaU Big Data cloud environment, SMT behaves very differently. Create an SMT engine with clean training data that's focused on the task at hand, and the engine can easily generate 30%, 40%, 50%, and more suggestions that translators accept out of the engine as correct.
I agree with you. In the near- to mid-term, adapting the engine to the translator will yield the highest benefits. Fixed adaptation can optimize the core engine to generate in the 30% to 50% range. Then, marry the core with dynamic on-the-fly adaptation and the technology augments the translator's work for the not-correct segments. Finally, when that marriage is in place, NMT's true value will shine to improve to set a new core baseline.
1) What is a "Human Translator"?
ReplyDeleteI always find it funny how technology developers are very careful and adamant about (often artificially) differentiating various aspects and/or generations of their own technology, but in their comparisons lump up the competition into a one big and amorphous entity.
A "human translator" in and of itself is not a benchmark for the very simple reason that not all humans, and not even all those who claim to be translators, are competent at translation and therefore the quality they produce covers the entire quality spectrum: From unusable garbage to the very best. The fact some piece of text was translated by some random human doesn't mean that particular piece of translation is automatically considered top-notch (or even fit for purpose), nor a representative demonstration of translation skills.
It's easy enough to compare MT to low quality/mediocre translation, which is generally the quality most of those dealing with MT have access to, and paint a favorable picture.
It is like the age-old question of "Is $XXX enough?"; Enough for what? Context is important, especially when comparing things. Anyone who claims to be offering translation services should know this, and if they don't, well... you are probably the product.
Most of the MT-related "studies" and "researches" I've seen so far are so devoid of a scientifically valid methodology that they are nothing more than advertorials and an insult to intelligence.
2) Not only that the rating methodology is flawed in the way described above, but all rating systems (which are in essence just polling of opinions) are flawed because the party commissioning the poll could affect the results by design: The way information is presented; leading questions; and so on.
3) Computers are good at solving many to one functions (such as Speech Recognition, OCR) and far less useful for solving one to many functions. A neural network is just an algorithm with better recursive capabilities and some autonomous scalability. When working and applied correctly it might be better at extracting information than previous solutions, but it is just as limited at creating information. Translation is a one to many function, and despite best of efforts to claim MT is an IT, i.e. Big Data, problem it will remain a communication problem. Neural Networks don't change that and MT continues to be a garbage-in-garbage-out type of process that relies on existing data, while languages and social-economical-business trends are ever developing.
MT might have its applications in Big Data driven processes, but it is not indistinguishable from real translation also because they are not serving the same markets and purposes.
Hello Shai
DeleteAll very good points. I do know that most if not all MT developers use price and speed as key determinants in selecting the translators they choose to get "gold standard" reference data. And you are right in pointing out that design of the polling has clear ulterior motives.
This objective, consistent and repeatable human assessment process can only come from competent translators and linguists, not from MT system developers who all seem to take shortcuts, to get it over with.
Great article Kirti. It wouldn't hurt at all to bring some MT claims closer to reality so that the industry would not be disoriented by empty promises!
DeleteThanks for the comment. I am going to bet that Ray Kurzweil is wrong even he adds another 10 years. But I agree that perhaps the most disturbing thing about this is that the press bought the story hook, line and sinker. Nobody sought to trust but verify. And clearly almost nobody understands this kind of geeky data presentation to make any kind of critical comment.You may be right about post-editing and that is why for the short term my money is still on Adaptive MT where the marketing has been truly disappointing and underwhelming.
ReplyDeleteRegarding "Do the green chunks look like they could possibly be 55% or more of the blue chunk?", I would say "no" - but that 55% does indeed look about like the % of (the green level minus the blue level) with respect to the (orange level minus the blue level). In other words, what is commonly known as the relative error, assuming that the human level is perfect, has decreased by over 50%. It is, however, still disingenuous of Google to (a) use relative error decrease instead of absolute error increase, which is what most people understand by "% error", and (b) assume that human level is perfect, when it is known not to be, except in the translation of very simple text. In the end what is important about the accuracy of MT is the human time saved in the overall translation process. So long as there remains a need for a human to check the translation at all, that time saved will never fall to anywhere near zero. On the other hand, when an approximate translation is sufficient, perhaps because the human using it is knowledgeable enough about the domain concerned to detect any gross translation errors, Google MT is already extremely useful. I use it regularly. There have been times when it has reversed the sense of a statement by somehow missing a "not" in translation, but often an approximate translation is enough for the human receiver to be able to correct such errors with very little effort. The danger, at present, arrises when the human receiver has complete confidence in the translation, but in that case it is not only the machine which is dumb, but also the human.
ReplyDeleteAndrew, I concede that strictly speaking the calculation used is not "wrong", it is just disingenuous and maybe even deceptive. Thank you for a very interesting comment.
DeleteAndrew, Google's analysis is valid for the 500 hand-selected sentences. Attempts to extrapolate those results to predict performance across billions and billions of transactions is hyperbole. I'll "translate" Slator.com's title from MT hyperbole to political hyperbole (after all, it is the season): "Dewey Defeats Truman." The Chicago Daily Tribune based this headline on their first-ever telephone poll of voters. In those days, mostly rich Republicans owned telephones. The poll's results accurately predicted the Republican vote count, but were unrepresentative of the larger voting population. The Tribune learned its lesson on November 3, 1948. Will Slator.com learn here?
DeleteLuigi, there are several references also available that suggest he is often wrong e.g. http://ow.ly/xaDG304OUWP and this more recent one http://ow.ly/4sp7304OV70. Given the terrible record pretty much everyone has had with MT I am betting that this is one he misses. I once met somebody from DARPA who said that most of the technological fantasy concepts from the science fiction show Star Trek would be possible to develop in some form in the next 25 years, except for the Universal Translator which might never happen.
ReplyDeleteAs Shai points out below - MT developers do not invest much in the HT references they use. I know as I have seen this first hand in several places. Anything quick and dirty would do. It is all about finding data and better algorithms. Some better assessment methodology is desperately needed.
This sentence was just pointed out to me after this post went live thus, I am adding an update as an in place postscript. The Nature (Journal of Science) http://nlp.hivefire.com/articles/share/64873/ provides a little more detail on the human testing process.
ReplyDelete"For some other language pairs, the accuracy of the NMTS approached that of human translators, although the authors caution that the significance of the test was limited by its sample of well-crafted, simple sentences."
Would this not constitute academic fraud? So now we have them saying both that the "raters" did not understand the sentences and that the sentences were essentially made simple i.e. rigged. To get a desirable and publishable result? For most in the academic community this would be enough to give pause, and be very careful about making any claims, but of course not for Google who look suspiciously like they did engineer "the" results at a research level.
Kirti, I guess it would be fraud if it were not for the presence of that sentence. "Read the fine print" comes to mind. I also think that my comment to Andrew about mismatched sample populations applies here. Ultimately, it's Google's money. For whatever reason, they committed to NMT for EN-ZH. I think you gave some sound analysis about possible reasons. It's also possible they're using the production environment to refine their engineering on the back-end. Time will tell.
DeleteFirst, a question, is the GNMT up and running already? I would like to test it. Second, I would like to comment on one revealing sentence from the Google NMT team: "We observed that human raters, even though fluent in both languages, do not necessarily fully understand each randomly sampled sentence sufficiently”. IMHO, randomly sampled sentences are difficult to fully understand if they are taken out of context. Is is not actually one of the shortcoming of MT, that it does have problems with grasping the intended meaning of linguistic utterances, because it does not understand context? So if you don't give the human raters the context that is necessary to understand a sentence, how can they "sufficiently" understand it? And what for heavens sake does "sufficiently understand" even mean? If you tell somebody "jump out of the window" and he does not jump, has he not sufficiently understood the meaning of your sentence? Maybe there is no window. Whatever. At least, It becomes clear to me that I do not sufficiently understand the meaning of the above sentence. It also becomes clear that human raters seems to be a kind of nuisance for machine translation developers. But then, who is supposed to understand and rate machine translations? Machines? Well, if it's machines talking to machines, I think there is a solution to it called binary code.
ReplyDeleteThe only GNMT system that is running is English <> Chinese one. The others have either not reached a threshold of improvement yet to warrant the huge increase in processing back end. The table 10 restatement shows you a more accurate picture of the facts at hand and explains why Chinese is the only one in production so far. This probably requires a huge increase in the processing back end.
DeleteThanks Kirsti for your interesting analysis. I'd just like to say that this kind of fraud reminds me of Aesops tale "The boy who cried Wolf". The day will come when those who buy from these fraudsters won't listen to them anymore. And that will be it.
ReplyDeleteIn science, being a serious scientist is a must. Your reputation can follow you for ever if you are careless or sloppy. Imagine the consequences of sheer fraud. And serious journalism likes to listen to serious scientists, as you have quoted from "Nature", reputation can be contagious (or worth adopting).
In the end I trust everything will find its proper place. However, your effort to educate us will help us get there sooner.
Re: Shai's Q "What is a human translator?" Yesterday I was at a presentation by the author of a book on China, and in one slide she had the word "partial" (blah-blah). Someone questioned/challenged her use of the word "partial", thinking she meant "not the whole" or "not completely." She explained she meant partial in the sense of "favorable to" or "giving preference to."
ReplyDeleteHere, I think the term "human translator" is probably a human participant in a study, not necessarily a professional translator. In years past (not recently) I used to lurk on the Mechanical Turk crowdsourced job-task site. I seem to remember translation tasks and text comparison tasks. Probably if I was doing a study comparing machine language translations and I needed several hundred or even several thousand participants, I'd go to a site like MTurk and make some sort of 'must understand Chinese and English and be a native speaker of English' qualification. So in this case, the emphasis is on the human and the interpretation of translator is different from what you might think, i.e., a professional translator.
Now, whether using crowdsourced participants for this kind of study is going to give accurate data is a whole other discussion. But pragmatically speaking, the only affordable way to conduct these kinds of studies is with crowdsourcing of a large population, such as that found on MTurk.
Barbara Werderitsch
ReplyDeleteDear Kirti - what an interesting article - I need to read it a second time, many new concepts for me;-) Yet touching on my profession as a translator and interpreter. Which is why I would like to ask you about the possibility of sharing it in our (Non-Profit) Translations Commons LinkedIn group? I will send you an invitation to it right now and hope you might want to join us;-)
Best regards,
Barbara
ReplyDeleteSally Blaxland
Like Barbara, I found this an intriguing article, although there is much on the technical side that I do not understand. Congratulations in any case, Kirti, on your attempt to bring possibly fraudulent misrepresentation to light. There is too much of that around these days, not only in research and commerce, but also in politics, and it can have disastrous results.
The deception is mostly around the human evaluation which presented the raters with a very ambiguous task. Then these results were used to make some rather aggressive claims that just don't seem warranted by the quality of the new GNMT which you can see in http://kv-emptypages.blogspot.com/2016/10/feedback-on-google-neural-mt-deception.html
DeleteAs it has been pointed out, human assessments of quality, as in "which of these two translations better" or "how good is this translation" all have two problems:
ReplyDelete(a) there does not seem to be any explicit reference to the purpose or intent of the translations: translations that are great for some applications may be inadequate for other applications. Imagine a machine translation system from Russian to English that gets very good translations, except for the fact it gives up trying to produce articles like "the", "a" and "some" which have no obvious equivalent in the source Russian text. The text would be very useful for gisting purposes, as any proficient English reader is used to this kind of language (for instance, in newspaper headlines), but it would be disaster if it has to be postedited, as words like "a", "the", etc., account for about 12% of English text. Conversely, some "machine translationese" may damage the usefulness of a text for gisting purposes, but seasoned posteditors may easily spot this kind of errors and correct them without even thinking (like getting "I eat" for "como" in Spanish, when most times it is not a verb but a function word that is translated "like" or "as").
(b) Any "judgement" is just that, a judgement. If an MT system is built to improve the productivity of professional translation, then what counts is the actual measured increase in productivity, not the "perception of productivity" that may come from a judgement. If the system is built for gisting purposes and therefore its translation is going to be used raw, what counts is the usefulness of that raw text for whatever the intended task is, not the "perception of usefulness" that comes from a judgement.
Unless the MT field comes up with a good way to train and tune machine translation systems, that is, one that is based on metrics that effectively track and predict measured usefulness in whatever the application is, the whole research field may be running around in circles.
But still people get very excited about statistically significant increases of one BLEU point and some even call it "a significant improvement in quality".
Anna Lein Dear Kirti, it is just like google to boldly go and brag and trump about something that even the IBM Watson still can not phantom although his creators have fed him all the literature of the world- so they say. Yet, for me, a translation that is better from his previous one only by 20 or even 80 percent is basicly like a person that is still learning the language and thus can not be a translator. And to invoke the words of Caliban from the Tempest :
ReplyDeleteWhen thou cam'st first,
Thou strok'st me and madest much of me, wouldst
give me
Water with berries in 't, and teach me how
To name the bigger light and how the less,
That burn by day and night.
This is how google trans has improved- steel after all Prospero's efforts- a child !
Very interesting .. I would just like to say, very quickly, that perhaps technology developers and the people in MT, which have all my respect, overlook the simple fact that languages evolve day to day, that to have an accurate, seamless translation in two languages you have to consider the final reader/listener to apply several types and varieties of techniques, that one simple word could have several different meaning, depending on the region and country, that context is much important, as it is the sense and meaning of words, just to mention a few; so, for a machine, it will be quite an effort to be precise, and this can be applied in most specialty translations; it can be as saying that they are going to create a robot tat will be able to perform a surgery .. with all due respect, I still believe mind and brain are marvelous .. MT still have a way to go .. they are useful, but limited
ReplyDeleteI've been using GNMT for Japanese > English for the last week or so and it's an absolute revelation. Words/hour is at least x5 if not more. I no longer need to translate, just proofread GNMT.
ReplyDeleteThanks, samuize, this is great feedback. Can you also report how many of your completed segments score zero edit distance relative to the GNMT output? I.e. what percent required no editing at all?
DeleteSamuize, what types of documents have you been translating? I'm a professional J>E translator and would like to compare notes.
DeleteHi! Hmm, when do you think machine translation will be flawless? Im guessing maybe 20 years
ReplyDeleteI am going to say never, but it is likely it will get really quite good in 20 years. How many humans translate flawlessly? See the problem?
DeleteThere is no accepted definition of what flawless is even for humans. If a computer does as well as an average moderately competent human I think there will be much celebration.
I have arrived slightly late to this article, and have limited experience of translation and how it is "tested": so forgive me if this doesn't add anything to the discussion.
ReplyDeleteHowever, it brings to mind a description in "The Book of Heroic Failures", published 1979, of an English-Portugese phrasebook written in 1883:
http://www.thepoke.co.uk/2016/03/03/english-as-she-is-spoke/
where the author only possessed Portugese-French and French-English dictionaries, and he went through those two stages to arrive at his translations.
How about using this instead? Run whichever phrase you like from one language to the other, then back again (or even via a third, intermediate language): then see if it's still comprehensible...
Perhaps this is already done: or has been shown not to work: if so, apologies; as I say, I am a complete novice in this field...
Anonymous, The scoring methodologies reported here are fine. There's nothing wrong with NMT and it has lots of promise for the future. However, our customers are translators. In their world, the only test that matters is how much effort the MT increases or reduces from their work today... not in some uncertain future.
ReplyDeleteThe BLEU scale is a "closeness" score, much like fuzzy matches. Fuzzy reports how closely the current source segment matches a source segment in the TM. We use the BLEU score post-facto to report how closely the MT suggestion matches translator's finished work. Note that in the reports above, the BLEU scores jump from mid-30's for cloud-based SMT to high-30's for cloud-based NMT. That's about a 25% increase in the score and impressive to many. Yet, assuming you're a translator, would you be satisfied with a source fuzzy closeness score in the mid- or high-30's? The best that cloud-based SMT/NMT can do is offer target closeness scores in this range.
We've taken SMT out of the cloud and embedded it into our desktop applications where one translator converts his own TMs to make one SMT engine that serves only him. In this use-case, the translator regularly experiences target closeness scores between the MT suggestion and their final work in the high 70's to high 80's. That's a 200% to 300% improvement over cloud-based SMT. It's the same fundamental SMT technology, totally different experience.
When NMT matures and is viable for this desktop application use case, it is certainly possible that it could push the target closeness scores even higher than we experience with SMT. Until then, I see no reason to downgrade our products and degrade our customers' experience with an NMT technology that is not ready for their needs.
As Pichai has learned, Big Tech companies can no longer skate by on faith in their fundamental benevolence. https://www.bloomberg.com/news/features/2017-10-19/everyone-s-mad-at-google-and-sundar-pichai-has-to-fix-it?stream=top-stories
ReplyDeleteKirti. Who was it who said: "Figures lie and Liars figure?" Good translation is an art, just as good writing is an art. Evaluating a good translation is essentially a subjective exercise. Reducing subjective evaluations to statistical data points is a risky enterprise. OK, often necessary and sometimes useful, but the results must be used with care. That is my take-away from your splendid article. I have been doing this for a good long time and I have tried - unsuccessfully, I'm afraid - to educate my clients that there are more than one or two levels of translation. Several years ago I participated in a project to translate a 1000+ page specifications manual for the construction of a Suez-max oil tanker. GNMT would have been highly suited for this project. But my bread and butter is economic and political analysis, which is less suited to GNMT. Sometimes I am called upon to do art criticism and philosophical treatises where GNMT simply cannot be relied upon. "You pays you money and you takes you choice." I have found GNMT to be very good at what it does, and getting better all the time, but it should not be asked to do what it simply cannot do without a very, very careful proof-read. pdw
ReplyDelete