This is a guest post by "Vova" from SmartCAT. I connected with him on Twitter and learned about the SmartCAT product which I would describe as a TMS + CAT tool with a much more substantial collaboration framework than most translation tools I know of. It is a next-generation translation management tool that enables multi-user collaboration at a large project level, but also allows individual freelancers to use it as a simple CAT tool. It has a new and non-standard approach to pricing which I am still trying to unravel. I have talked to one LSP customer, who was very enthusiastic about his user experience and stressed the QA and productivity benefits especially for large projects. I am still researching the product and company (which has several ex-ABBYY people but they seem eager to develop a separate identity) and will share more as I learn more. But on first glance, this product looks very interesting and even compelling, even though, they, like Lilt, have a hard time describing what they do quickly and clearly. Surely they should both be looking to hire a marketing consultant - I know one who comes to mind ;-). The most complete independent review on the SmartCAT product (requires a subscription), is from Jost Zetzsche who likes it, which to my mind is meaningful commendation for them, even though he likes other products too.
Many translators are wary of CAT tools. They feel that computer-aided translation commoditizes and takes the creativity out of the profession. In this article, we will try to clear up some common misconceptions that lead to these fears.
In reality, machine translation is just a part — in most cases a small part — of what computer-aided translation is about. This part is usually called “PEMT” (post-editing of machine translation) and consists in correcting a translation done by one or another MT engine. We’re nowhere near replacing a human translator with a machine.
PEMT itself is like a red flag to a bull for many translators and deserves a separate article. Here we will just reiterate that equating CAT with machine translation is like equating aviating skills with using the autopilot.

This “repetition handling” feature is commonly called Translation Memory (TM). Now, TM is a large part of what CAT tools do (and why they were created in the first place). But today it is just a feature, with many others supplementing it.
In SmartCAT, for instance, we have project management, terminology, quality assurance, collaboration, marketplace, and many other features. All these features are carefully integrated with each other to form a single whole that is SmartCAT and that distinguishes us from the competition. If it were all about translation memory, there would be nothing to compete about.
So, why would you use a CAT tool in a “serious” translation? Here’s a very “serious” book on numismatics I translated some time ago. I made it all in SmartCAT. Why? Because I would have never managed to keep this amount of terminology in my head. Even if I used Excel sheets to keep track of all the terms — ancient kings, regions, coin names, weight systems — it would’ve taken me dozens of hours of additional work. In SmartCAT, I had everything within arm’s reach in a glossary that was readily accessible and updateable using simple key combinations.
Another reason CAT tools can be useful for “serious” translations is quality assurance. Okay, MS Word has a spellchecker. There is also third-party software that provides more sophisticated QA capabilities. And still, having it right at hand, with downloadable reports and translation-specific QA rules is something only a good CAT tool can boast (more on this later).
For now, we’ll just say that there is no reason why a translator should not use a CAT tool for their own projects. If anything, it provides a distraction-free interface where one can concentrate on the work in question and not think about secondary things such as formatting, file handling, word counting, and so on.

Luckily, today users have plenty of options to choose from. And although the de rigueur names remain the same (so far), many modern CATs are as easy to learn as a text processor or a juicer (though some of those can be tricky, too). Here’s a video of going all the way from signing up to downloading the final document in SmartCAT in less than one minute. It’s silent and not subtitled, but sometimes looks are more telling than words:
In any case, there are still options for you to go (and grow) even if you don’t want to spend on unpredictably profitable assets. SmartCAT is free for both freelancers and companies. The only thing you might opt to pay for is machine translation and image recognition. And, if you decide to market your services via the SmartCAT marketplace, a 10% commission (payable by the customer) will be added on top of your own rate. That’s it — no hidden fees involved.
Here’s an example. The last project I made in SmartCAT was a one-page financial document in Excel format. To translate it, I uploaded the file to SmartCAT and already had all the translation memories, terminology, word count, etc. ready. So I just did the translation, downloaded the result and sent it back with an invoice.
If I went the “simple” way, I would have spent some valuable minutes — which are the more valuable the smaller a project is — on organizational “overheads.” Putting the files in the right place in the file system. Looking for previous translations to align the terminology. Finally, doing the translation in Excel, which is a torture in itself.
In CAT tools, whether it is an Excel file, a Powerpoint presentation, a scanned PDF (for CAT tools supporting OCR, e.g. SmartCAT), you still have the same familiar two-column view for any of them. As already said, you concentrate on words, not formats.
Thus,

becomes

— in mere seconds!
The reality is quite different. In SmartCAT, for instance, the configuration needed to start a project includes a minimum number of choices. Moreover, all the resources you need are added automatically according to the customer’s name. That saves time in addition to the streamlining of the very translation process.

That’s what I did for a children’s book I translated recently. I made the several first “runs” in SmartCAT. Then I downloaded the result and had it reviewed several more times (and once by a native speaker). When everything was ready, I got the whole thing back to SmartCAT. Why? Because I want to translate the next part of the book. I know I will have forgotten a lot by the time it comes, so having all the previous resources at hand will be very helpful for the quality.
Speaking of quality, modern CAT tools also allow a great degree of quality assurance, with some checking rules fine-tuned for translation tasks. Using those is much more convenient and practical than resorting to spellcheckers available in office software or externally.

The argument is that translation technology deprives translators of their bread. And instead of being there for translators’ growth and profit, it grows and profits at their expense. Customers get pickier, rates get lower, translations becomes a commodity.
In my humble opinion, CAT tools are as bad for translators as hair-cutting shears are for hairdressers. Perhaps, doing a haircut with a butcher’s knife could be more fun. You could even charge more for providing such an exclusive service. But it has little to do with the profession of cutting hair (or translating). A professional strives to increase the efficiency of their work. Using cutting-edge tools is one way to do this. A very important one, that.
Yes, it can be argued that CAT tools bring down your average per-word rate. But as Gert van Assche aptly puts it, the time you spend on a job is the only thing you need to measure. I can’t say for everyone, but my own hourly rates soar with the use of CAT tools. I know that I can provide the best quality in the shortest time possible. I also know that I don’t charge unnecessarily high rates to my long-time customers, whose attitude I care about a lot.
That’s it — I hope I did manage to clear away your fears about computer-aided translation.
Remember, if you’re not using CAT tools, you are falling behind your colleagues, who might be equally talented but just a bit tech-savvier.
A good CAT tool will aid your growth as a professional and a freelancer. After all, aiding translators is what the whole thing is about.
P.S. If you never tried CAT tools at all, or did but didn’t enjoy the experience, I suggest that you check out SmartCAT now — it’s simple, powerful, and free to use.

Vladimir “Vova” Zakharov is the Head of Community at SmartCAT.
"Translation is my profession and my passion, and I’m excited to be able to share it with the amazing SmartCAT community!"
--------------
Many translators are wary of CAT tools. They feel that computer-aided translation commoditizes and takes the creativity out of the profession. In this article, we will try to clear up some common misconceptions that lead to these fears.
1 — Computer-aided translation is the same as machine translation
The naming of the term “computer-aided translation” often leads to its being confused with “machine translation.” The first thing some of our new users write us is “why don’t I see the automatic translation in the right column”? For some reason, they expect it to be there (and perhaps replace the translation effort at all?).In reality, machine translation is just a part — in most cases a small part — of what computer-aided translation is about. This part is usually called “PEMT” (post-editing of machine translation) and consists in correcting a translation done by one or another MT engine. We’re nowhere near replacing a human translator with a machine.
PEMT itself is like a red flag to a bull for many translators and deserves a separate article. Here we will just reiterate that equating CAT with machine translation is like equating aviating skills with using the autopilot.
Here’s where you find it, just in case — but use cautiously.
2 — Computer-aided translation is all about handling repetitions
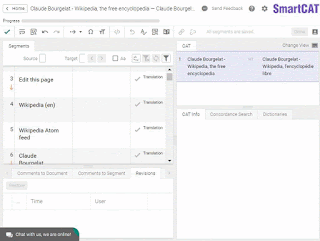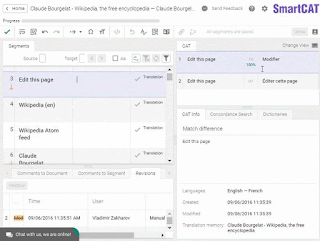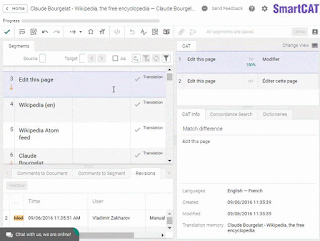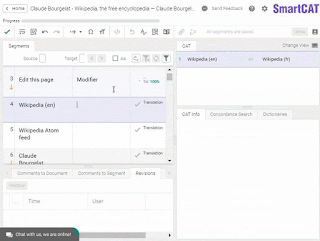
Another widespread misconception is that CAT tools are only used to handle repetitive translations. What does it mean? Say, you have the same disclaimer printed in the beginning of each book of a given publisher. Someone would then need to translate it only once, and a CAT tool would automatically insert this translation in each new translated book of that publisher.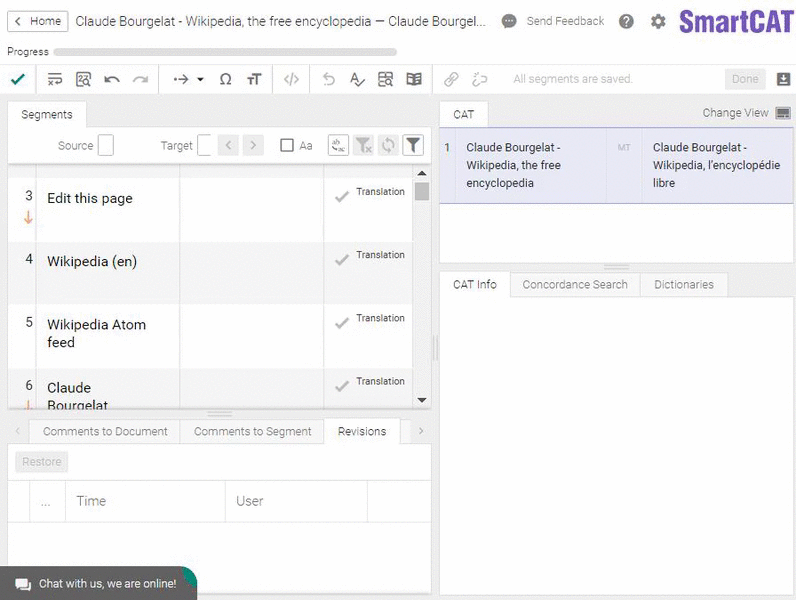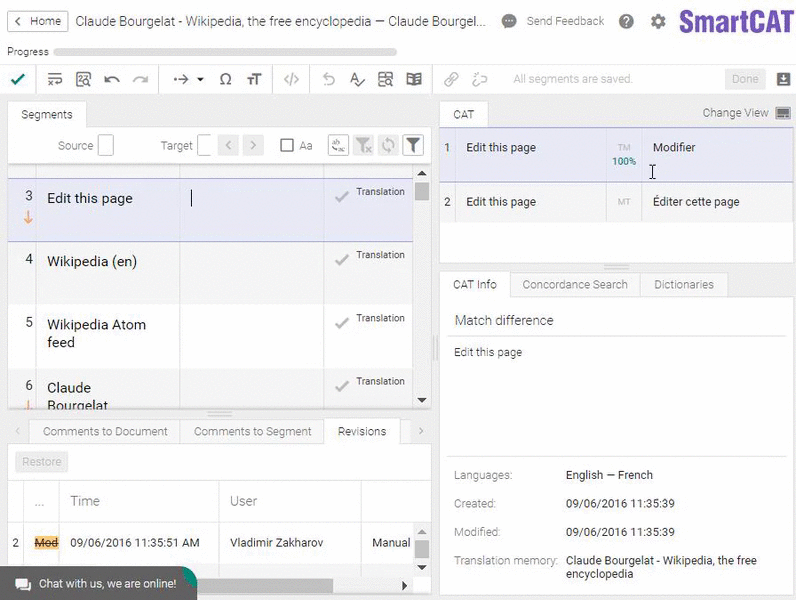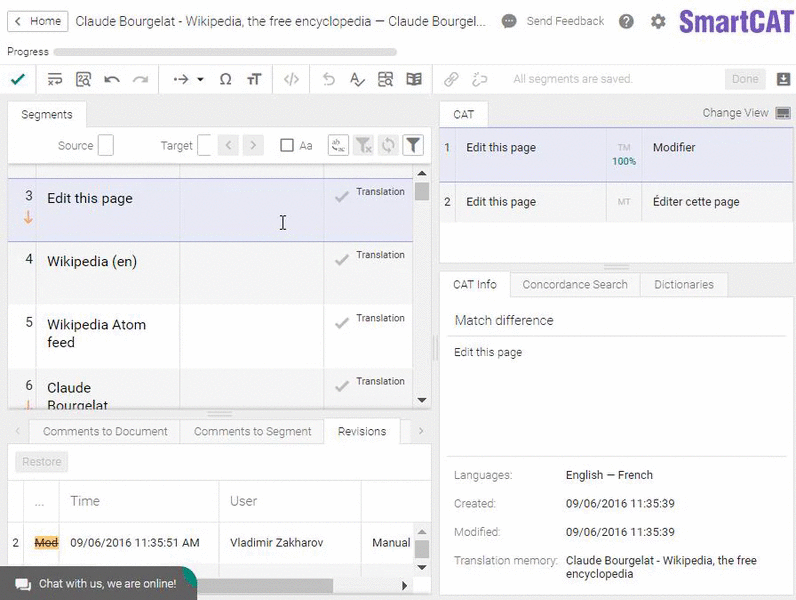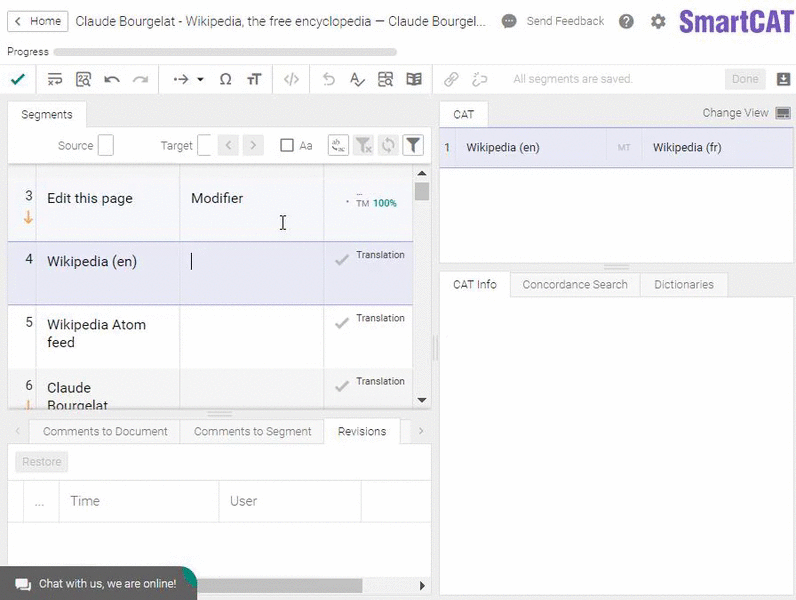
Here’s what a TM match looks like. (That’s an easy one.)
This “repetition handling” feature is commonly called Translation Memory (TM). Now, TM is a large part of what CAT tools do (and why they were created in the first place). But today it is just a feature, with many others supplementing it.
In SmartCAT, for instance, we have project management, terminology, quality assurance, collaboration, marketplace, and many other features. All these features are carefully integrated with each other to form a single whole that is SmartCAT and that distinguishes us from the competition. If it were all about translation memory, there would be nothing to compete about.
3 — Computer-aided translation doesn’t work for “serious” translations
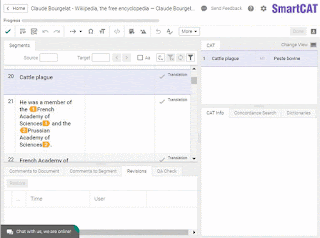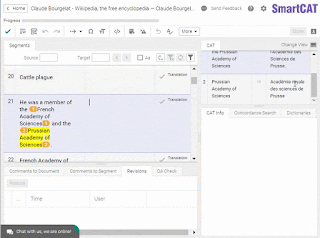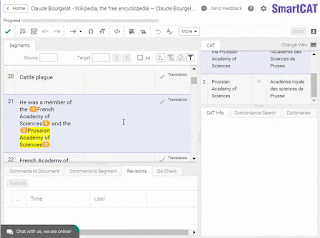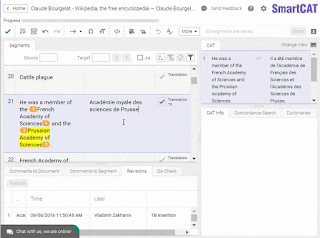
Some believe that “serious” translators (whatever that means) do not use CAT tools. The truth is that “purists” do exist, just as they do in any other field, from religion to heavy metal. But not using a CAT tool as a translator is close to not using a cellphone as a CEO. According to a 2013 study by Proz, 88% of translators were using CAT tools, and we can only expect the numbers to have gone up since then.So, why would you use a CAT tool in a “serious” translation? Here’s a very “serious” book on numismatics I translated some time ago. I made it all in SmartCAT. Why? Because I would have never managed to keep this amount of terminology in my head. Even if I used Excel sheets to keep track of all the terms — ancient kings, regions, coin names, weight systems — it would’ve taken me dozens of hours of additional work. In SmartCAT, I had everything within arm’s reach in a glossary that was readily accessible and updateable using simple key combinations.

Inserting a glossary term in SmartCAT
Another reason CAT tools can be useful for “serious” translations is quality assurance. Okay, MS Word has a spellchecker. There is also third-party software that provides more sophisticated QA capabilities. And still, having it right at hand, with downloadable reports and translation-specific QA rules is something only a good CAT tool can boast (more on this later).
4 — CAT tools are for agencies only
Many translators receive orders from agencies dictating the use of one CAT tool or another. So they start thinking that “all these CATs” are an “agency thing” and are meant to make use of them. We’ll leave that latter argument aside for a while and come back to it later.For now, we’ll just say that there is no reason why a translator should not use a CAT tool for their own projects. If anything, it provides a distraction-free interface where one can concentrate on the work in question and not think about secondary things such as formatting, file handling, word counting, and so on.

Note the tags (orange pentagons): You don’t need to care what formatting there was in the original.
5 — CAT tools are hard to learn
Well, that’s not exactly a myth. I remember my first experience with a prominent CAT tool (it was some ten years ago). I cried for three days, considering myself a worthless piece of junk for not being able to learn something everyone around seemed to be using. When the tears dried out, I went for some googling and realized that I wasn’t the only one to struggle with the mind-boggling interfaces of the software that was en vogue back then.Luckily, today users have plenty of options to choose from. And although the de rigueur names remain the same (so far), many modern CATs are as easy to learn as a text processor or a juicer (though some of those can be tricky, too). Here’s a video of going all the way from signing up to downloading the final document in SmartCAT in less than one minute. It’s silent and not subtitled, but sometimes looks are more telling than words:
6 — CAT tools are ridiculously expensive
Another myth that is partly true is that CAT tools cost a freaking lot. Some do. The cheapest version of the most popular desktop computer-aided translation software costs around $500. One of the most popular subscription-based solutions costs nearly $30 a month. It’s probably okay if you have a constant inflow of orders and some savings to afford the purchase (and perhaps a personal accountant). But what if you are just starting out? Or if you are an occasional semi-pro translator? Not that okay, then.In any case, there are still options for you to go (and grow) even if you don’t want to spend on unpredictably profitable assets. SmartCAT is free for both freelancers and companies. The only thing you might opt to pay for is machine translation and image recognition. And, if you decide to market your services via the SmartCAT marketplace, a 10% commission (payable by the customer) will be added on top of your own rate. That’s it — no hidden fees involved.
7 — Computer-aided translation works for large projects only
If you think that CAT tools work best for huge projects, you might be right. If you think they don’t work for small projects at all, you are wrong.Here’s an example. The last project I made in SmartCAT was a one-page financial document in Excel format. To translate it, I uploaded the file to SmartCAT and already had all the translation memories, terminology, word count, etc. ready. So I just did the translation, downloaded the result and sent it back with an invoice.
If I went the “simple” way, I would have spent some valuable minutes — which are the more valuable the smaller a project is — on organizational “overheads.” Putting the files in the right place in the file system. Looking for previous translations to align the terminology. Finally, doing the translation in Excel, which is a torture in itself.
In CAT tools, whether it is an Excel file, a Powerpoint presentation, a scanned PDF (for CAT tools supporting OCR, e.g. SmartCAT), you still have the same familiar two-column view for any of them. As already said, you concentrate on words, not formats.
Thus,

becomes

8 — Computer-aided translation slows you down
Despite evidence, some translators believe that using CAT tools will actually reduce their translation speed. The logic is that in a CAT tool you have to start a project, configure all its settings, find the TMs and terminology you need to reuse, and so on. In the end, they say, you they spend more time doing this than what they will save as a result.The reality is quite different. In SmartCAT, for instance, the configuration needed to start a project includes a minimum number of choices. Moreover, all the resources you need are added automatically according to the customer’s name. That saves time in addition to the streamlining of the very translation process.

8 seconds to create a project with a translation memory and terminology glossary in place
9 — CAT tools worsen the quality of translation
Some believe that by not seeing the whole text, you lose its “flow.” This, they argue, leads to errors in the style and narrative of translation. While this is true in some cases (e.g. for literary translation), the fact is that the “flow” is anyway disturbed by your seeing the original text. It always makes sense to have at least one purely proofreading stage in the end, when you don’t see the original. Then you can judge the text solely on the basis of how good or bad it sounds in the target language.That’s what I did for a children’s book I translated recently. I made the several first “runs” in SmartCAT. Then I downloaded the result and had it reviewed several more times (and once by a native speaker). When everything was ready, I got the whole thing back to SmartCAT. Why? Because I want to translate the next part of the book. I know I will have forgotten a lot by the time it comes, so having all the previous resources at hand will be very helpful for the quality.
Speaking of quality, modern CAT tools also allow a great degree of quality assurance, with some checking rules fine-tuned for translation tasks. Using those is much more convenient and practical than resorting to spellcheckers available in office software or externally.

QA rules available in SmartCAT. Some are more paranoid than the others.
10 — Computer-aided translation is bad for translators
That’s the underlying cause for many of the above misconceptions. Some translators fear that computer-aided translation is bad for the profession as a whole. Here’s a very illustrative post by Steve Vitek, a long-time opponent of translation technology. (Interestingly, the post includes many of the views countered above. I’d love to see Steve’s comment on this article of mine. Can my arguments make him change his mind, I wonder?)The argument is that translation technology deprives translators of their bread. And instead of being there for translators’ growth and profit, it grows and profits at their expense. Customers get pickier, rates get lower, translations becomes a commodity.
In my humble opinion, CAT tools are as bad for translators as hair-cutting shears are for hairdressers. Perhaps, doing a haircut with a butcher’s knife could be more fun. You could even charge more for providing such an exclusive service. But it has little to do with the profession of cutting hair (or translating). A professional strives to increase the efficiency of their work. Using cutting-edge tools is one way to do this. A very important one, that.
Yes, it can be argued that CAT tools bring down your average per-word rate. But as Gert van Assche aptly puts it, the time you spend on a job is the only thing you need to measure. I can’t say for everyone, but my own hourly rates soar with the use of CAT tools. I know that I can provide the best quality in the shortest time possible. I also know that I don’t charge unnecessarily high rates to my long-time customers, whose attitude I care about a lot.
That’s it — I hope I did manage to clear away your fears about computer-aided translation.
Remember, if you’re not using CAT tools, you are falling behind your colleagues, who might be equally talented but just a bit tech-savvier.
A good CAT tool will aid your growth as a professional and a freelancer. After all, aiding translators is what the whole thing is about.
P.S. If you never tried CAT tools at all, or did but didn’t enjoy the experience, I suggest that you check out SmartCAT now — it’s simple, powerful, and free to use.
----------
About the author

Vladimir “Vova” Zakharov is the Head of Community at SmartCAT.
"Translation is my profession and my passion, and I’m excited to be able to share it with the amazing SmartCAT community!"














