As outlined in a previous post,
the global data explosion is creating new challenges for the legal industry that requires balancing the use of emerging technologies and human resources in optimal ways to handle the data deluge effectively.
The continuing digital communication momentum and
the much more rapid pace of globalization today often create specialized
legal challenges. The rapid increase in global business interactions,
varying regulatory laws, business practices, and cultural customs of
international partners and competitors are confounding and often
frustrating to participants. The impact of all these concurrent trends
is driving the volume of cross-border litigation up, and necessitates
that corporate general counsel in global enterprises, and large law
firms find the means to perform the critical functions related to manage
the unique requirements of legal eDiscovery in these particular
scenarios.
A recent Norton Rose Fulbright survey of litigation trends highlights the need for technology to enhance efficiency in legal departments and also points out the growth of cybersecurity and data protection disputes increasing across all industries. Additionally, the survey states that increasingly, international business operations lead to an increase in cross-border discovery and related data protection issues. The survey found that within the life sciences and healthcare and technology and innovation
sectors, the most concerning area is IP/Patent disputes. IP/Patent
disputes are regarded as relatively costly in comparison to other legal
matters, and technology and life sciences companies, in particular, face
large exposure in this area.
By understanding
the unique discovery requirements of different regions, instilling
transparency and consistency throughout the discovery team and process,
and taking advantage of powerful technology and workflow tools,
companies can be better equipped to meet the discovery demands of
litigation and regulatory investigations. The multilingual impact of
this data deluge is just now being understood, and as we move to a
global reality where the largest companies and markets in the globe are
increasingly not English-speaking regions, the ability to handle huge
volumes of flowing multilingual data become a way to build competitive
advantage, and avoid becoming commercially irrelevant. Being able to
handle large volumes of multilingual data effectively is a critical
requirement for the modern enterprise.

What is eDiscovery?

The processes and technologies around eDiscovery are often complex because of the sheer volume/variety of electronic data produced and stored. Additionally, unlike hard-copy evidence, electronic
documents are more dynamic and often contain metadata such as time-date
stamps, author and recipient information, and file properties.
Preserving the original content and metadata for electronically stored
information is required to eliminate claims of spoliation or tampering
with evidence later in a litigation scenario.
EDiscovery is typically a culling process, of moving from unstructured to structured data – from unstructured data to matter-specific relevance, and the highest value and most directly relevant information.

Thus, while there are three primary activities typically in eDiscovery, namely, collection, processing, and review, it is clear to practitioners and analysts that the review-related activity is the bulk of the cost of the overall eDiscovery process.
One analyst estimates that review-related software and services are estimated to constitute approximately 70% of worldwide eDiscovery software and services spending in 2018. While the percentage of spending on the eDiscovery task of review is estimated to decrease to around 65% of overall eDiscovery spending through 2023, the overall spend in dollars for eDiscovery review is estimated to grow to $12.15B by 2023.
A respected RAND Institute study is even more explicit about the costs and shows very clearly that managing your data volume is critical to managing your costs. The Rand Institute for Civil Justice estimates that the per-gigabyte costs break down to $125 to $6,700 for collection, $600 to $6,000 for processing, and, in the most expensive stage, $1,800 to $210,000 for review. The costs for multilingual review are very likely even higher and by some estimates could be as much as 3X times higher.
This
means that a conscientious, defensible, proactive approach to
information governance can lead to tremendous savings. Every gigabyte of
outdated unnecessary ESI that you delete in following a uniform data
destruction policy saves you, on average, $18,000 per case.

It is possible to identify the critical steps involved in a
typical multilingual eDiscovery use case where the key objective is to
extract the most relevant information form a large volume of submitted
material. The multilingual characteristics of much of the data that
needs to be reviewed today adds a significant layer of complexity and an additional cost to the process.

The typical process involves the following key steps:
EDiscovery is typically a culling process, of moving from unstructured to structured data – from unstructured data to matter-specific relevance, and the highest value and most directly relevant information.

Thus, while there are three primary activities typically in eDiscovery, namely, collection, processing, and review, it is clear to practitioners and analysts that the review-related activity is the bulk of the cost of the overall eDiscovery process.
One analyst estimates that review-related software and services are estimated to constitute approximately 70% of worldwide eDiscovery software and services spending in 2018. While the percentage of spending on the eDiscovery task of review is estimated to decrease to around 65% of overall eDiscovery spending through 2023, the overall spend in dollars for eDiscovery review is estimated to grow to $12.15B by 2023.
A respected RAND Institute study is even more explicit about the costs and shows very clearly that managing your data volume is critical to managing your costs. The Rand Institute for Civil Justice estimates that the per-gigabyte costs break down to $125 to $6,700 for collection, $600 to $6,000 for processing, and, in the most expensive stage, $1,800 to $210,000 for review. The costs for multilingual review are very likely even higher and by some estimates could be as much as 3X times higher.
"The RAND Institute for Civil Justice has estimated that each gigabyte of data reviewed costs a company approximately $18,000."
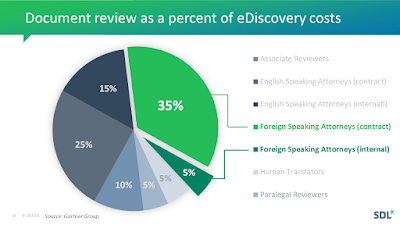
What is document review?
Also known simply as review, document review is the stage of the EDRM in which organizations examine documents connected to a litigation matter to determine if they are relevant, responsive, or privileged.
The value of having robust information governance policies in place makes the overall process both more effective and more efficient. Due to outsourcing and the high cost of using lawyers, document review is the most expensive stage of eDiscovery. It is generally responsible for 70%
or more of the total cost of eDiscovery.
The
cost per hour for document review attorneys to review documents during
the review phase of eDiscovery is one of the most expensive steps in the
overall process, something which is only further exacerbated when the
attorneys have to be bilingual at a high level of proficiency.


To
control those extravagant costs, litigants strive to narrow the field
of documents that they must review. The processing stage of eDiscovery
is intended in large part to eliminate redundant information and to
organize the remaining data for efficient, cost-effective
document review. Technology that assists in the culling and close examination process is essential, and we see that eDiscovery platforms
that assist professional services, law firms, and information technology
organizations to find, store, review and create legal documents are
increasingly pervasive.
Document
review can be used in more than just legal eDiscovery for litigation.
It may also be used in regulatory investigations, internal investigations, and due diligence assessments for mergers and acquisitions and other information governance-related activities. Wherever it is employed, it serves the same purpose of designating information for production and requires a similar approach.
The Multilingual eDiscovery process

- Text Extraction: It is often necessary to extract multilingual text from scanned documents to ensure that all relevant documents are identified and sent to review. OCR technology and native file processing technology to enable an enterprise to do this at scale. Sometimes it is also required to extract text from audio.
- Automated Language Identification Processing: Linguistic AI technology capabilities make automatic detection of languages and data sets within any content an efficient and highly automated process.
- Multilingual Search Term Optimization: Linguists work together with MT experts to generate critical search and terminology to ensure that multilingual data goes through optimal discovery related processing. This ensures that high volume automatic translations get critical terminology correct, and also enables the most relevant foreign language data to be discovered and presented for timely review. The multilingual search term consultant’s understanding of linguistic and cultural nuances can mean the difference between capturing critical information and missing it completely. Competent linguists ensure that grammatical, linguistic and cultural issues are taken into consideration during search term list development.
- Secure, Private, State-of-the-Art Machine Translation: Firms should work and develop secure, private, scalable enterprise-ready MT technology that can be deployed on-premise or in the private cloud. Integration with Relativity (and other eDiscovery platforms) makes it easy for companies to handle anything related to large corporate legal matters, from analyzing and translating millions of documents to preparing critical contracts and court-presentable documents.
- Specialized Human Translation Services: Many firms provides around-the-clock, around-the-world service using state-of-the-art linguistic AI tools to ensure greater accuracy, security reduced costs and turnaround time. The company has a pool of certified and specialized translators across multiple jurisdictions and languages worldwide who have expertise and competence across a wide range of legal documents. The company is already working with 19 of the top 20 law firms in the world. The translation supply chain is often the hidden weak spot in an organization's data compliance. Several firms provide a secure translation supply chain that gives you fully auditable, data custody of your translation processes and can be cascaded down through your outside counsel and consultants to create a replicable process across all of your legal service partners.














