Recently I came upon this little tidbit and initially thought how wonderful, (NMT is surely rising!) and decided to take a closer look and read through the research paper. This exercise left me a little uncertain as I now felt doubt, and began to suspect that this is just another example of that never-ending refrain of the MT world, the empty promise. Without a doubt Google had made some real progress, but “Nearly Indistinguishable From Human Translation” and “GNMT reduces translation errors by more than 55%-85% on several major language pairs “. Hmmm, not really, not really at all, was what my pesky brain kept telling me, especially as I saw this announcement coming up again and again through many news channels, probably pushed heavily by the Google marketing infrastructure.
Surely the great Google of the original “Don’t Be Evil” ethos would not bullshit us thus. (In their 2004 founders' letter prior to their initial public offering, Larry Page and Sergey Brin explained that their "Don't be evil" culture prohibited conflicts of interest, and required objectivity and an absence of bias.) Apparently, Gizmodo already knew about the broken promise in 2012. My friend Roy told me that: Following Google's corporate restructuring under the conglomerate Alphabet Inc. in October 2015, the slogan was replaced in the Alphabet corporate code of conduct by the phrase "Do the right thing". However, to this day, the Google code of conduct still contains the phrase "Don't be evil”. This ability to conveniently bend the rules (but not break the law) and make slippery judgment calls which are convenient to corporate interests, is well described by Margaret Hodge in this little snippet. Clearly, Google knows how to push self-congratulating, mildly false content through the global news gathering and distribution system by using terms like research and breakthrough with somewhat shaky research data that includes math, sexy flowcharts, and many tables showing “important research data”. They are after all the kings of SEO. However, I digress.
The basic deception I speak of, and yes I do understand that those might be strong words, is the overstatement of the actual results, using questionable methodology, in what I would consider an arithmetical manipulation of the basic data, to support corporate marketing messaging spin (essentially to bullshit the casual, trusting, but naïve reader who is not aware of the shaky foundations at play here and of statistics in general). Not really a huge crime, but surely just a little bit evil and sleazy. Not quite the Wells Fargo, Monsanto, Goldman Sachs and Valiant & Turing Pharmaceuticals (medical drug price gouging) level of evil and sleazy but give them time and I am sure they could rise to this level, and they quite possibly will step up their sleaze game if enough $$$s and business advantage issues are at stake. AI and machine learning can be used for all kinds of purposes both sleazy or not as long as you have the right power and backing.
So basically I see three problems with this announcement:
 Take a look at the bar chart they provide below and tell me if any of the bars looks like there was a “55% to 85%” improvement from the blue line (PBMT) to the top of the green line (GNMT). Do the green chunks look like they could possibly be 55% or more of the blue chunk? I surely don’t see it until I put my Google glasses on.
Take a look at the bar chart they provide below and tell me if any of the bars looks like there was a “55% to 85%” improvement from the blue line (PBMT) to the top of the green line (GNMT). Do the green chunks look like they could possibly be 55% or more of the blue chunk? I surely don’t see it until I put my Google glasses on.

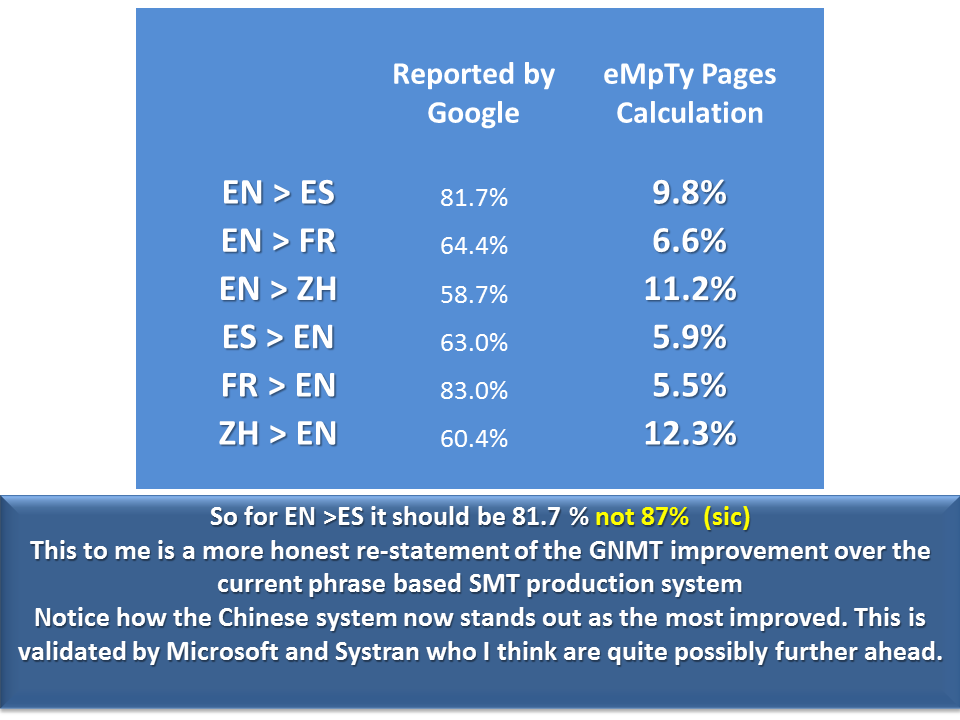
I think it is worth restating the original data in Table 10, in what to me is a much more forthright, accurate, reasonable, and less devious presentation shown below. Even though I remain deeply skeptical about the actual value of humans rating multiple translations of the same source sentence on a scale on 0 to 6. These restated results are also very positive so I am not sure why one would need to overstate these unless there was some marketing directive behind it. Also, these results point out that the English <> Chinese system experienced the biggest gains which both Microsoft and SYSTRAN have already confirmed and also possibly explains why it is the only GNMT system in production. For those who believe that Google is the first to do this, this is not so, both Facebook and Microsoft have production NMT systems running for some time now.
 When we look at how these systems are improving with the commonly used BLEU score metric, we see that the progress is much less striking. MT has been improving slowly and incrementally as you can see from the EN > FR system data that was provided below. To put this is some context, Systran had an average of 5 BLEU points improvement on their NMT systems over the previous generation V8 systems. Of course, not the same training/test data and technically not exactly equivalent for absolute comparison, but the increase is relative to their old production systems and is thus a hyperbole-free statement of progress.
When we look at how these systems are improving with the commonly used BLEU score metric, we see that the progress is much less striking. MT has been improving slowly and incrementally as you can see from the EN > FR system data that was provided below. To put this is some context, Systran had an average of 5 BLEU points improvement on their NMT systems over the previous generation V8 systems. Of course, not the same training/test data and technically not exactly equivalent for absolute comparison, but the increase is relative to their old production systems and is thus a hyperbole-free statement of progress.

 The Google research team uses human rating since BLEU is not always reliable and has many flaws and most of us in the MT community feel that competent human assessment is a way to keep it real. But this is what Google say about the human assessment result: “Note that we have observed that human raters, even though fluent in both languages, do not necessarily fully understand each randomly sampled sentence sufficiently and hence cannot necessarily generate the best possible translation or rate a given translation accurately.” They provide a table to show some samples of where they disagree. Would that not be a clue to suggest that the side-by-side comparison is flawed? So what does this mean? The human rating was not really competent? The raters don’t understand the machine’s intent and process? That this is a really ambiguous task so maybe the results are kind of suspect even though you have found a way to get a numerical representation of a really vague opinion? Or all of the above? Maybe you should not show humans multiple translations of the same thing and expect them to score them consistently and accurately.
The Google research team uses human rating since BLEU is not always reliable and has many flaws and most of us in the MT community feel that competent human assessment is a way to keep it real. But this is what Google say about the human assessment result: “Note that we have observed that human raters, even though fluent in both languages, do not necessarily fully understand each randomly sampled sentence sufficiently and hence cannot necessarily generate the best possible translation or rate a given translation accurately.” They provide a table to show some samples of where they disagree. Would that not be a clue to suggest that the side-by-side comparison is flawed? So what does this mean? The human rating was not really competent? The raters don’t understand the machine’s intent and process? That this is a really ambiguous task so maybe the results are kind of suspect even though you have found a way to get a numerical representation of a really vague opinion? Or all of the above? Maybe you should not show humans multiple translations of the same thing and expect them to score them consistently and accurately.
Could it be that they need a more reliable human assessment process and maybe they should call Juan Rowda and Silvio Picinini at eBay and ask them how to do this correctly or at least read their posts in this blog. Or maybe they can hire competent translators to guide this human evaluation and assessment process instead of assigning “human raters” a task that simply does not make sense, no matter how competent they are as translators.
In the grand scheme of things, the transgressions and claims made in this Google announcement are probably a minor deception but I still think they should be challenged and exposed if possible, and if it is actually fair criticism. We live in a world where corporate malfeasance has become the norm of the day. Here we have a small example which could build into something worse. Monsanto, Well Fargo, Goldman Sachs do not have evil people (maybe just at the top) but they have a culture that rewards certain kinds of ethically challenged behavior if it benefits the company or helps you “make your numbers”. To me, this is an example in-kind and tells you something about the culture at Google.
We are still quite a long way from “Nearly Indistinguishable From Human Translation”. We need to be careful about overstating the definite and clear progress that actually has been made in this case. For some reason, this (overstatement of progress) is something that happens over and over again in MT. Keep in mind that drawing such sweeping conclusions on a sample of 500 is risky with big data applications (probably 250 Million+ sentence pairs) even when the sample is really well chosen and the experiment has an impeccable protocol which in this case is SIMPLY NOT TRUE for the human evaluation. The rating process is flawed to such an extent that we have to question some or many of the conclusions drawn here.The most trustworthy data presented here are the BLEU scores assuming it is truly a blind test set and no Google glasses were used to peek into the test.
This sentence was just pointed out to me after this post went live, thus, I am adding an update as an in place postscript. Nature (Journal of Science) provides a little more detail on the human testing process.
These results are consistent with what SYSTRAN has reported (described here ), and actually are slightly less compelling at a BLEU score level than the results SYSTRAN has had as I explained above. (Yes Mike I know it is not the same training and test set.)
Now that I have gotten the rant off my chest, here are my thoughts on what this “breakthrough” might mean:
The marketing guy at Google who pushed this announcement in its current form should be asked to watch this video (NSFW link, do NOT click on it if you are easily offended) at least 108 times. The other guys should also watch it a few times too. Seriously, let’s not get carried away just yet. Let’s wait to hear from actual users and let’s wait to see how it works in production use scenarios before we celebrate.
As for the Google corporate motto, I think it has been already true for some time now that Google is at least slightly evil, and I recommend you watch the three-minute summary by Margaret Hodge to see what I mean. Sliding down a slippery slope is a lot easier than standing on a narrow steep ledge in high winds. In today's world, power and financial priorities rule over ethics, integrity and principal and Google is just following the herd that includes their friends at Well Fargo, Goldman Sachs, VW, and Monsanto. I said some time ago that a more appropriate motto for Google today might actually be: “You Give, We Take.” Sundar should walk around campus in a T-shirt (preferably one made by underpaid child labor in Bangladesh) with this new motto boldly emblazoned on it in some kind of a cool Google font. At least then Google marketing would not have to go through the pretense of having any kind of ethical, objective or non-biased core which the current (original) motto forces them to contend with repeatedly. The Vedic long view of the human condition across eons, says we are currently living in the tail end of the Kali Yuga, an age of darkness and falsehood and wrong values. An age when charlatans (Goldman Sachs, VW, Monsanto, Wells Fargo and Google) are revered and even considered prophets. Hopefully, this era ends soon.
Florian Faes has made a valiant effort to provide a fair and balanced view on these claims from a variety of MT expert voices. I particularly enjoyed the comments by Rico Sennrich of the University of Edinburgh who cuts through the Google bullshit most effectively. For those who think that my rant is unwarranted, I suggest that you read the Slator discussion, as you will get a much more diverse opinion. Florian even has rebuttal comments from Mike Schuster at Google whose responses sound more than a little bit like the spokespersons at Well Fargo, VW and Goldman Sachs to me. Also, for the record, I don’t buy the Google claim “Our system’s translation quality approaches or surpasses all currently published results,” unless you consider only their own results. I am willing to bet $5 that both Facebook and Microsoft (and possibly Systran and Baidu) have equal or better technology. Slator is the best thing that has happened to the “translation industry” in terms of relevant current news and investigative journalism and I hope that they will thrive and succeed.
I remain willing to stand corrected if my criticism is unfounded or unfair, especially if somebody from Google sets me straight. But I won’t hold my breath, not until the end of the Kali Yuga anyway.
PEACE.

Surely the great Google of the original “Don’t Be Evil” ethos would not bullshit us thus. (In their 2004 founders' letter prior to their initial public offering, Larry Page and Sergey Brin explained that their "Don't be evil" culture prohibited conflicts of interest, and required objectivity and an absence of bias.) Apparently, Gizmodo already knew about the broken promise in 2012. My friend Roy told me that: Following Google's corporate restructuring under the conglomerate Alphabet Inc. in October 2015, the slogan was replaced in the Alphabet corporate code of conduct by the phrase "Do the right thing". However, to this day, the Google code of conduct still contains the phrase "Don't be evil”. This ability to conveniently bend the rules (but not break the law) and make slippery judgment calls which are convenient to corporate interests, is well described by Margaret Hodge in this little snippet. Clearly, Google knows how to push self-congratulating, mildly false content through the global news gathering and distribution system by using terms like research and breakthrough with somewhat shaky research data that includes math, sexy flowcharts, and many tables showing “important research data”. They are after all the kings of SEO. However, I digress.
The basic deception I speak of, and yes I do understand that those might be strong words, is the overstatement of the actual results, using questionable methodology, in what I would consider an arithmetical manipulation of the basic data, to support corporate marketing messaging spin (essentially to bullshit the casual, trusting, but naïve reader who is not aware of the shaky foundations at play here and of statistics in general). Not really a huge crime, but surely just a little bit evil and sleazy. Not quite the Wells Fargo, Monsanto, Goldman Sachs and Valiant & Turing Pharmaceuticals (medical drug price gouging) level of evil and sleazy but give them time and I am sure they could rise to this level, and they quite possibly will step up their sleaze game if enough $$$s and business advantage issues are at stake. AI and machine learning can be used for all kinds of purposes both sleazy or not as long as you have the right power and backing.
So basically I see three problems with this announcement:
- Arithmetic manipulation to create the illusion of huge progress. (Like my use of font size and bold to make the word huge seem more important than it is.)
- Questionable human evaluation methodology which produces rating scores that are then further arithmetically manipulated and used to support the claims of “breakthrough” progress. Humans are unlikely to rate 3 different translations of the same thing on a scale of 0 to 6 (crap to perfect) accurately and objectively. Ask them to do it 500 times and they are quite likely to give you pretty strange and illogical results. Take a look at just four pages of this side-by-side comparison and see for yourself. The only case I am aware of where this kind of a translation quality rating was done with any reliability and care was by Appen Butler Hill for Microsoft. But translation raters there were not made to make a torturous comparison of several versions of the same translation, and then provide an independent rating for each. Humans do best (if reliable and meaningful deductions are sought from the exercise) when asked to compare two translations and asked a simple and clear question like: “Which one is better?” Interestingly even the Google team noted that: “We observed that human raters, even though fluent in both languages, do not necessarily fully understand each randomly sampled sentence sufficiently”. Yes, seriously dude, are you actually surprised? Methinks that possibly there is a kind of stupor that sets in when one spends too much time in the big data machine learning super-special room, that numbs the part of the brain where common sense resides.
- Then taking this somewhat shaky research and making the claim that the GNMT is “Nearly Indistinguishable From Human Translation” and figuring out a way to present this as “55% to 85%” improvements.
Marketing Deception = fn (small BLEU improvements, shaky human evaluation on a tiny amount of data that sort of support our claim, math formulas, very sexy multimedia flow chart, lots of tables and data to make it look like science, HUGE amount of hyperbole, SEO marketing so everybody publishes it, like it was actually a big breakthrough and meaningful research.)
Arithmetic Manipulation
So onto some specifics. Here is the table that provides the “breakthrough results” to make the over-the-top claims. They did not even bother to do the arithmetic correctly on the first row! Seriously, are they not allowed to use Excel or at least a calculator? :

I think it is worth restating the original data in Table 10, in what to me is a much more forthright, accurate, reasonable, and less devious presentation shown below. Even though I remain deeply skeptical about the actual value of humans rating multiple translations of the same source sentence on a scale on 0 to 6. These restated results are also very positive so I am not sure why one would need to overstate these unless there was some marketing directive behind it. Also, these results point out that the English <> Chinese system experienced the biggest gains which both Microsoft and SYSTRAN have already confirmed and also possibly explains why it is the only GNMT system in production. For those who believe that Google is the first to do this, this is not so, both Facebook and Microsoft have production NMT systems running for some time now.

The Questionable Human Side-by-Side Evaluation
I have shared several articles in this blog about the difficulties of doing human evaluations of MT output. It is especially hard when humans are asked to provide some kind of a (purportedly objective) score to a candidate translation. While it may be easier to rank multiple translations from best to worst (like they do in WMT16), the research shows that this is an area plagued with problems. Problems here means it is difficult to obtain results that are objective, consistent and repeatable. This also means that one should be very careful about drawing sweeping conclusions from such questionable side-by-side human evaluations. This is also shown by some of the Google research results as shown below which are counter-intuitive.
Could it be that they need a more reliable human assessment process and maybe they should call Juan Rowda and Silvio Picinini at eBay and ask them how to do this correctly or at least read their posts in this blog. Or maybe they can hire competent translators to guide this human evaluation and assessment process instead of assigning “human raters” a task that simply does not make sense, no matter how competent they are as translators.
In the grand scheme of things, the transgressions and claims made in this Google announcement are probably a minor deception but I still think they should be challenged and exposed if possible, and if it is actually fair criticism. We live in a world where corporate malfeasance has become the norm of the day. Here we have a small example which could build into something worse. Monsanto, Well Fargo, Goldman Sachs do not have evil people (maybe just at the top) but they have a culture that rewards certain kinds of ethically challenged behavior if it benefits the company or helps you “make your numbers”. To me, this is an example in-kind and tells you something about the culture at Google.
We are still quite a long way from “Nearly Indistinguishable From Human Translation”. We need to be careful about overstating the definite and clear progress that actually has been made in this case. For some reason, this (overstatement of progress) is something that happens over and over again in MT. Keep in mind that drawing such sweeping conclusions on a sample of 500 is risky with big data applications (probably 250 Million+ sentence pairs) even when the sample is really well chosen and the experiment has an impeccable protocol which in this case is SIMPLY NOT TRUE for the human evaluation. The rating process is flawed to such an extent that we have to question some or many of the conclusions drawn here.The most trustworthy data presented here are the BLEU scores assuming it is truly a blind test set and no Google glasses were used to peek into the test.
This sentence was just pointed out to me after this post went live, thus, I am adding an update as an in place postscript. Nature (Journal of Science) provides a little more detail on the human testing process.
"For some other language pairs, the accuracy of the NMTS approached that of human translators, although the authors caution that the significance of the test was limited by its sample of well-crafted, simple sentences."Would this not constitute academic fraud? So now we have them saying both that the "raters" did not understand the sentences and that the sentences were essentially made simple i.e. rigged. To get a desirable and publishable result? For most in the academic community this would be enough to give pause and reason to be very careful about making any claims, but of course not for Google who looks suspiciously like they did engineer "the results" at a research level.
These results are consistent with what SYSTRAN has reported (described here ), and actually are slightly less compelling at a BLEU score level than the results SYSTRAN has had as I explained above. (Yes Mike I know it is not the same training and test set.)
Now that I have gotten the rant off my chest, here are my thoughts on what this “breakthrough” might mean:
- NMT is definitely proving to be a way to drive MT quality upward and forward but for now, is limited to those with deep expertise and access to huge processing and data resources.
- NMT problems (training and inference speed, small vocabulary problem, missing words etc..) will be solved sooner rather than later.
- Experiment results like these should be interpreted with care, especially if they are based on such an ambiguous human rating score system. Don’t just read the headline and believe them, especially when they come from people with vested interests e.g. Google.
- Really good MT always looks like human translation, but what matters is how many segments in a set of 100,000 look like a human translation. We should save our "nearly indistinguishable" comments for when we get closer to 90% or at least 70% of all these segments being almost human.
- The success at Google, overstated though it is, has just raised the bar for both the Expert and especially the Moses DIY practitioners, which makes even less sense now since you could almost always do better with generic Google or Microsoft who also has NMT initiatives underway and in production.
- We now have several end-to-end NMT initiatives underway and close to release from Facebook, Microsoft, Google, Baidu, and Systran. For the short term, I still think that Adaptive MT is more meaningful and impactful to users in the professional translation industry, but as SYSTRAN has suggested, NMT "adapts" very quickly with very little effort with small volumes of human corrective input. This is a very important requirement for MT use in the professional world. If NMT is as responsive to corrective feedback as SYSTRAN is telling us, I think we are going to see a much faster transition to NMT.
The marketing guy at Google who pushed this announcement in its current form should be asked to watch this video (NSFW link, do NOT click on it if you are easily offended) at least 108 times. The other guys should also watch it a few times too. Seriously, let’s not get carried away just yet. Let’s wait to hear from actual users and let’s wait to see how it works in production use scenarios before we celebrate.
As for the Google corporate motto, I think it has been already true for some time now that Google is at least slightly evil, and I recommend you watch the three-minute summary by Margaret Hodge to see what I mean. Sliding down a slippery slope is a lot easier than standing on a narrow steep ledge in high winds. In today's world, power and financial priorities rule over ethics, integrity and principal and Google is just following the herd that includes their friends at Well Fargo, Goldman Sachs, VW, and Monsanto. I said some time ago that a more appropriate motto for Google today might actually be: “You Give, We Take.” Sundar should walk around campus in a T-shirt (preferably one made by underpaid child labor in Bangladesh) with this new motto boldly emblazoned on it in some kind of a cool Google font. At least then Google marketing would not have to go through the pretense of having any kind of ethical, objective or non-biased core which the current (original) motto forces them to contend with repeatedly. The Vedic long view of the human condition across eons, says we are currently living in the tail end of the Kali Yuga, an age of darkness and falsehood and wrong values. An age when charlatans (Goldman Sachs, VW, Monsanto, Wells Fargo and Google) are revered and even considered prophets. Hopefully, this era ends soon.
Florian Faes has made a valiant effort to provide a fair and balanced view on these claims from a variety of MT expert voices. I particularly enjoyed the comments by Rico Sennrich of the University of Edinburgh who cuts through the Google bullshit most effectively. For those who think that my rant is unwarranted, I suggest that you read the Slator discussion, as you will get a much more diverse opinion. Florian even has rebuttal comments from Mike Schuster at Google whose responses sound more than a little bit like the spokespersons at Well Fargo, VW and Goldman Sachs to me. Also, for the record, I don’t buy the Google claim “Our system’s translation quality approaches or surpasses all currently published results,” unless you consider only their own results. I am willing to bet $5 that both Facebook and Microsoft (and possibly Systran and Baidu) have equal or better technology. Slator is the best thing that has happened to the “translation industry” in terms of relevant current news and investigative journalism and I hope that they will thrive and succeed.
I remain willing to stand corrected if my criticism is unfounded or unfair, especially if somebody from Google sets me straight. But I won’t hold my breath, not until the end of the Kali Yuga anyway.
PEACE.










