As more of the global population comes online, people need MT to access the content that interests them even if only in a gist-sense, and today we see that there is growing momentum in the development and advancement of the state-of-the-art (SOTA) on “low-resource” (languages with limited or scarce data) languages to further accelerate global MT use.
MT technology has been around in some form for the last 70 years and unfortunately has a long history of over-promising and under-delivering. A history of eMpTy promises as it were. However, the more recent history of data-driven MT has been especially troubling for translators, as SMT and NMT pioneers have repeatedly claimed to have reached human parity.
These over-exuberant claims about the accomplishment of MT technology, have driven translator compensation down and have made many would-be translators reconsider their career choices.
It does not help that a more careful examination of the human parity claims by experts shows that these claims are not true, or perhaps only true for a tiny sample of test sentences.
Many say, that the market perception of exaggerated MT capabilities has damaged translator livelihood and there is often great frustration by many who use MT in production environments where the high-quality human equivalent translation is expected but never delivered, without significant additional effort and expense.
To add insult to injury, the overly optimistic MT performance claims have also resulted in many technology-incompetent LSPs attempting to use MT to reduce costs by forcing translators to post-edit low-quality MT output at low rates.
It does not seem to matter that most LSPs have yet to properly learn to use MT in localization production work, according to a survey of MT use by LSPs done by Common Sense Advisory last year.
It is also very telling that the author wrote a blog post on MT post-editing compensation in March 2012 that has had the widest readership of any post he has written ever, and continues even in 2022 to be an actively read post!
Thus, often "monolithic MT" is considered a dark, unuseful, and unwelcome factor in the lives of translators. However, this state of affairs is often a result of incompetent and unethical use of the technology rather than a core technology characteristic.
The Content and Demand Explosion
However, the news on MT is not all doom and gloom from the translator's perspective. There is a huge demand for language translation as evidenced by the volume of use of public MT, and by the digital transformation imperatives for global enterprises driving the need for better professional MT.
Both public MT and enterprise MT are building momentum. The demand for content from across the globe is exponential which means that translation volumes will also likely explode. And, while much of it can be handled with carefully optimized Enterprise MT, it will also need an ever-growing pool of tech-savvy translators to drive continuously improving MT technology.
World Bank estimates say that by 2022, yearly total internet traffic is projected to increase by about 50 percent from 2020 levels, reaching 4.8 zettabytes, equal to 150,000 GB per second. The growth in global internet traffic is as dazzling as the volume. Personal data are expected to represent a significant share of the total volume of data being transferred cross-border.
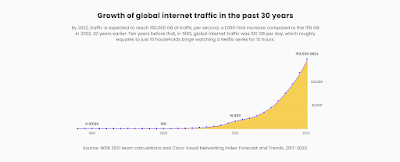
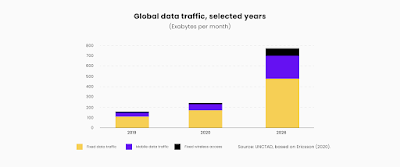
The sheer volume and explosion in content volumes driven by these trends are already creating an increasing awareness of the supply shortage of translators. The furor around the poor quality of the translation of the Korean hit show “Squid Games” is a telling example of this changing scene.
LSPs and translators are critical to the distribution of that local content on a global scale. But because of a labor shortage and no viable automated solution, the translation industry is being pushed to its limits.
“I can tell you literally, this industry will be out of supply over demand for the upcoming two to three years,” David Lee, the CEO of Iyuno-SDI, one of the industry’s largest subtitling and dubbing providers, said recently. “Nobody to translate, nobody to dub, nobody to mix –– the industry just doesn’t have enough resources to do it.” Interviews with industry leaders reveal most streaming platforms are now at an inflection point, left to decide how much they are willing to sacrifice on quality to subtitle their streaming roster.
So while it is true that as we enter 2022 most LSPs have yet to learn how to use MT efficiently for production use, and that translator compensation at the word level has been decreasing over the last five years, there are also positive changes.
The Translated Srl experience with ModernMT shows that it is possible to use MT effectively for production localization work as Translated uses MT in 95% of their production workload, mainly because the technology is flexible, easy to set up, highly responsive, and agile enough to handle the variations typical in production work.
This is the result of superior architecture, better process integration, and sensitivity to human factors, refined over decades, to ensure sustainable and increasing productivity improvements.
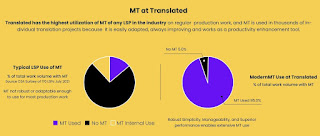
The Translated Srl experience is also direct proof that MT can be a valuable assistive technology tool for serious, i.e. professional human translation work.
The ModernMT technology is perhaps the only MT technology optimized for production localization work and is already in the process of being extended to work with video content (MateDub & MateSub). Video adds time synchronization challenges to the basic translation tasks.
The Importance of the Human-In-The-Loop
The exploding content and enterprise CX demands to provide more relevant content to their customers also suggests that there is a potential for rates to rise as more enterprises begin to understand that improving translation quality has to be linked to an increased role of humans-in-the-loop to make MT perform better on the specific content that matters to the enterprise.
As we consider the possibility of MT achieving human parity on language translation at production scale we need to remind ourselves of the following. Language is the cornerstone of human intelligence.
The emergence of language was the most important intellectual development in our species’ history. It is what separates us from all other species on the planet. It is through language that we formulate thoughts and communicate them to one another. Language enables us to reason abstractly, to develop complex ideas about what the world is and could be, and to build on these ideas across generations and geographies. Almost nothing in modern civilization would be possible without language.
Building machines that can “understand” language has thus been a central goal of the field of artificial intelligence dating back to its earliest days, but this has proven to be maddeningly elusive. The current state of MT is the result of 70 years of effort, and having a machine master language may either be impossible or simply much farther out in the future than the ML-focused singularity-is-nigh fanboys can envision.
This is because mastering language is what is known as an “AI-complete” problem: that is, an AI that can understand language the way a human can, would by implication be capable of any other human-level intellectual activity. Put simply, to solve the language challenge is to create human-equivalent machine intelligence.
Competent linguistic feedback is needed to improve the state of MT technology, and humans are needed to improve the quality of MT output for enterprise use.
We see today that machine translation is ubiquitous, and by many estimates is responsible for 99.5% or more of all language translation done on the planet on any given day. But we also see that MT is used mostly to translate material that is voluminous, short-lived, transitory and that would never get translated if the machine were not available to help.
Trillions of words are being translated by MT weekly, yet when it matters, there is always human oversight on translations that may have a high impact, or when there is great potential risk or liability from mistranslation.
While machine learning use-cases continue to expand dramatically, there is also an increasing awareness that a human-in-the-loop is necessary since the machine lacks comprehension, cognition, and common sense, all elements that constitute “understanding”.
As Rodney Brooks, the co-founder of iRobot said in a post entitled - An Inconvenient Truth About AI: "Just about every successful deployment of AI has either one of two expedients: It has a person somewhere in the loop, or the cost of failure, should the system blunder, is very low."
Many of the public generic MT engines already have billions of sentence pairs that underlie and “train” the model. Yet, we see an increasing acknowledgment from the AI community that language is indeed a hard problem. One that cannot necessarily be solved by using more data and algorithms alone, and a growing awareness that other strategies will need to be employed.
This does not mean that these systems cannot be useful, but we are beginning to understand that while language AI tools are useful, they have to be used with care and human oversight, at least until machines have more robust comprehension and common sense.
Effective human-in-the-loop (HITL) implementations allow the machine to capture an increasing amount of highly relevant knowledge and enhance the core application as ModernMT does with MT.
Another way to look at this is to see the Language AI or MT model as a prediction system, rather than as a representative model of a human translator.
Very simply put, we are using information that we do have to generate information that we don’t have.
MT models are built primarily with translation memory (a.k.a training data) and are most successful with material that is most similar to this training data. MT models take the new source material and produce a prediction of this material into a target language based on what it knows from what it has been explicitly trained with.
With deep learning, pattern detection and prediction have gotten more sophisticated, but we are still, quite some distance from actual understanding, comprehension, and cognition.
A human translation cognitive flow within the brain of a competent human translator has significantly more sophisticated capabilities around the many translation-related sub-tasks that require and involve actual intelligence, gathered from multisensorial life experience and common sense.
Human translators understand the relevant document, historical, and situational context even though it may not be explicitly stated. They identify semantic intent, and add cultural context into the translation, reading between the lines to ensure overall accuracy, guided by common sense, on what may not be stated but can be “understood” from life experience, insight, and deep comprehension.
This is in stark contrast to just performing the literal conversion of word strings and patterns from the source language to a target language that MT systems are limited to. Systems trained on billions of example "training" sentences have yet to capture what humans do. More data is not enough.
To restate, it is more accurate to see the MT model as a prediction system rather than an understanding system. Much of the recent success with AI and machine learning is a result of converting problems that were not historically prediction problems into prediction problems e.g. self-driving cars, fraud detection, and automated email replies.
MT systems are most useful when they produce a large number of useful predictions, even if these are not "perfect". It is as useful for a translator as TM, maybe even more so, when MT is responsive, continuously learning, and a true assistant.
The overview of the development and deployment of the prediction model can be seen in this generic graphic overview which is true for MT and many other ML use cases.

Once a model has been deployed ongoing improvement in its prediction ability can be driven by more data, better learning algorithms, more computing power, and ongoing corrective feedback that becomes increasingly important as an ML model evolves in competence and performance.
The following chart shows what happens at the monitor stage where human judgment and active corrective feedback on model outputs begin to drive improvements on the specific material in focus. The best systems will take feedback and process, learn, update, and incorporate new learning quickly to improve the predictions of the model in real-time.

The speed and ease with which new learning can be incorporated into an MT system are critical determinants of the value of the MT system to an individual translator. There is great value for all stakeholders in improving the predictive capabilities of an MT system.
ModernMT: An MT system designed for the translator
The modern era translator work experience often involves the use of translation memory (TM). Since it improves translator productivity when the TM is related and relevant to any new translation work that a translator may undertake.
MT is used less often by professional translators in general because of the following reasons:
- Generic MT output is of limited value.
- Most MT systems have a very limited ability to customize and adapt the generic system to the translator's area of focus and specialization.
- The typically complex customization process often requires that translators have skills that are typically outside of the scope of translator education.
- A large volume of data (more than most translators can summon) is needed to have any impact on generic engine performance. This also makes it difficult for most LSPs to also customize an MT engine as most of the MT models in the market require tens of thousands or more segments of training data to have an impact.
- The very slow rate of improvement of most MT engines means that translators must correct the same errors over and over again. The whole improvement process can itself be a significant engineering undertaking and task.
- The open admission of MT use is often penalized with lower compensation and lower word rates.
- The inability to control and improve MT output predictably means that translators themselves have a higher level of uncertainty about the utility of MT given project deadlines and thus fallback to traditional approaches.
For MT to be useful to a translator it needs the following attributes:
- Tight integration with CAT tools that are the primary work environment for translators.
- Easy to start using without geeky technical preparation and ML-customization-related work.
- Rapid learning of new material and incorporation of any corrective feedback so that the MT system is continuously improving, by the day or even the hour.
- The ability to handle project-related terminology with ease.
- Keep translator data private and secure.
ModernMT is a translator-focused MT architecture that has been built and refined over a decade with active feedback and learning from a close collaboration between translators and MT researchers.
ModernMT has been used intensively in all the production translation work done by Translated Srl for over 15 years and was a functioning human-in-the-loop (HITL) machine learning system before the term was even coined.
ModernMT is perhaps the only MT system that was designed by translators for translators rather than by pure technologists working in isolation with data and algorithms.
This long-term engagement with translators and continuous feedback-driven improvement process also results in creating a superior training data set over the years. This superior training data enables users to have an efficiency and quality advantage that is not easily or rapidly replicated.
This is also the reason why ModernMT does so consistently well in third-party MT system comparisons, even though evaluators do not always measure its performance optimally. ModernMT simply has more informed translator feedback built into the system.
The following is a summary of features in a well-designed Human-in-the-loop (HITL) system, such as the one underlying ModernMT:
- Easy setup and startup process for any and every new adapted MT system that allows even a single translator to build hundreds of domain-focused systems.
- Responsive: Active and continuous corrective feedback is rapidly processed so that translators can see the impact of corrections in real-time and the system improves continuously without requiring the translator to set up a data collection and re-training workflow.
- An MT system that is continuously training and improving with this feedback (by the minute, day, week, month). Small volumes of correction can improve the ongoing MT performance.
- Tightly integrated into the foundational CAT tools used by translators who provide the most valuable system-enhancing feedback.
- Different engagement and interaction with MT than a typical PEMT experience.
I recently interviewed several translators who are active ModernMT users and have summarized their comments (+ve and -ve) below. Their comments contain pearls of wisdom and anecdotal experience that may be useful to other translators who are still considering MT.
Subject focus by those who shared their usage patterns with me included accounting/finance, legal contracts, complex engineering equipment-related content, marketing content, product manuals, newsletters & press releases, medical information for patients, and even Buddhism & meditation-related content. Many simply provided categories like Law, Medical, Technical.
The extent of use: Used in the large majority of work they did, except for DTP or very specialized domain content that they did on an infrequent basis. Many said that the real benefits start to accrue after one builds up some TM and that over time ModernMT learns to support your primary workload.
How is MT engaged: CAT Tools (Trados), ModernMT GUI, and MateCat
Why: Work volumes and turnaround requirements and high-level data privacy and availability of TM to enable adaptation.
Competitive systems evaluated: Google, DeepL, Systran, Kantan
“I have used DeepL and Google, which can be very useful, although I still find ModernMT to have better overall accuracy compared to both of them. DeepL is a good alternative for comparing output, although it is much less consistent compared to ModernMT when working on large documents e.g. consistency of terminology etc.”
“I can tell you this with peace in my mind that nothing can replace ModernMT. ModernMT has magic that no one can describe. It really adapts to contexts and stores my previous translations and yields me 99% accurate translations.”
Improvements needed: Word case handling for acronyms and abbreviations, handling of short phrases and titles, the lack of persistence of terms across documents, better format preservation, better dashboard.
Desirable New features: Glossary and terminology handling, a dashboard on data and usage, more robust punctuation handling, real-time predictive capabilities, pre-translation quality assessment.
”I consider MT as a development tool, making our job easier, but not a tool that gives the final product. It is like an advanced medical tool used by a surgeon during surgery, which helps the surgeon to make fewer mistakes, to save time, and to save the life of the patient.”
A strong positive comment by a translator who also provided constructive areas of improvement content: “I have noticed incredible improvement [in the MT quality] as if it is my roommate who was trying to get to know me and my translation style and way of constructing the sentences.”
Many were surprised to find out that glossary and terminology terms are best introduced to ModernMT in sentence form rather than as short phrases as the context and variants shown in sentence-context ensures a faster pick-up and learning.
Several expressed surprise that more translators did not realize cost/benefit and productivity advantages to be gained by using a responsive MT system like ModernMT and also mentioned that success with ModernMT required investment in one or all of the following: time, corrective feedback, and personal TM but can yield surprisingly good results in as little as a few weeks.
To close this post I include a podcast done with ProZ last year, that I got very positive feedback on, from many translators.
Conversation with Paul Urwin of Proz on MT
Paul talks with machine translation expert Kirti Vashee about interactive-adaptive MT, linguistic assets, freelance positioning, how to add value in explosive content situations, e-commerce translation, and the Starship Enterprise.
Paul
continues the fascinating discussion with Kirti on machine translation.
In this episode, they talk about how much better MT can get, which
languages it works well for, data, content, pivot languages, and machine
interpreting.
