The holiday season around the world today is often characterized by special holiday shopping events like Black Friday and Cyber Monday. These special promotional events generate peak shopping activity and are now increasingly becoming global events. They are also increasingly becoming a digital and online commerce phenomenon. This is especially true in the B2C markets but is also now often true in the B2B markets.
The numbers are in, and the most recent data is quite telling. The biggest U.S. retail shopping holiday of the year – from Thanksgiving Day to Black Friday to Cyber Monday, plus Small Business Saturday and Super Sunday – generated $24.2 billion in online revenues. And that figure is far below Alibaba’s 11.11 Global Shopping Festival, which in 2018 reached $30.8 billion – in just 24 hours.

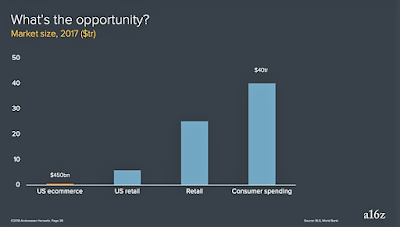
When we look at the penetration of eCommerce in the U.S. retail market, we see that, as disruptive as it has been, it is still only around 10% of the total American retail market. According to Andreessen Horowitz, this digital transformation has just begun, and it will continue to gather momentum and spread to other sectors over the coming years.
Success in online business is increasingly driven by careful and continued attention to providing a good overall customer experience throughout the buyer journey. Customers want relevant information to guide their purchase decisions and allow them to be as independent as possible after they buy a product. This means sellers now need to provide much more content than they traditionally have.
Much of the customer journey today involves a buyer interacting independently with content related to the product of interest, and digital leaders understand that understanding the customer and providing content that really matters to them is a pre-requisite for digital transformation success.
In a recent study focused on B2B digital buying behavior that was presented at a recent Gartner conference, Brent Adamson pointed out that “Customers spend much more time doing research online – 27% of the overall purchase evaluation and research [time]. Independent online learning represents the single largest category of time-spend across the entire purchase journey.”
The proportion of time 750 surveyed customers making a large B2B purchase spent working directly with salespeople – both in person and online – was just 17% of their total purchase research and evaluation process time. This fractional time is further diluted when you spread this total sales person contact time across three or more vendors that are typically involved in a B2B purchase evaluation.
The research made evident that a huge portion of a sellers’ contact with customers happens through digital content, rather than in-person. This means that any B2B supplier without a coherent digital marketing strategy specifically designed to help buyers through the buyer journey will fall rapidly behind those who do.
The study also found that just because in-person contact begins, it doesn’t mean that online contact ends. Even after engaging suppliers’ sales reps in direct in-person conversations, customers simultaneously continue their digital buying journey, making use of both human and digital buying channels simultaneously.
Today it is very clear to digitally-savvy executives that providing content relevant to the buyer journey really matters and is a key factor in enabling digital online success. A separate research study by Forrester uncovered the following key findings:
This requirement for providing so much multilingual content presents a significant translation challenge for any enterprise that seeks to build momentum in new international markets. To address this challenge, eCommerce giants like eBay, Amazon, and Alibaba are among the largest users of machine translation in the world today. There is simply too much content needs to be multilingual to do this with traditional localization methods.
However, even with MT, the translation challenge is significant and requires deep expertise and competence to address. The skills needed to do this in an efficient and cost-effective manner are not easily acquired, and many B2B sellers are beginning to realize that they do not have these skill in-house and could not effectively develop them in a timely manner.
The projected future growth of eCommerce activity across the world suggests that the opportunity in non-English speaking markets is substantial, and any enterprise with aspirations to lead – or even participate – in the global market will need to make huge volumes of relevant content available to support their customers in these markets.
When we look at eCommerce penetration across the globe, we see that the U.S. is in the middle of the pack in terms of broad implementation. The leaders are the APAC countries, with China and South Korea having particularly strong momentum as shown below. You can see more details about the global eCommerce landscape in the SDL MT in eCommerce eBook.

The chart below, also from Andreessen Horowitz shows the shift in global spending power and suggests the need for an increasing focus on APAC and other regions outside of the US and Europe. The recent evidence of the power of eCommerce in China shows that these trends are already real today and are gathering momentum.

As Andreesen points out, the digital disruption caused by eCommerce has only just begun and the data suggests that the market opportunity is substantially greater for those who have a global perspective. SDL's MT in eCommerce eBook provides further details on how a digitally-savvy enterprise can handle the new global eCommerce content requirements in order to partake in the $40 trillion global eCommerce opportunity.


The numbers are in, and the most recent data is quite telling. The biggest U.S. retail shopping holiday of the year – from Thanksgiving Day to Black Friday to Cyber Monday, plus Small Business Saturday and Super Sunday – generated $24.2 billion in online revenues. And that figure is far below Alibaba’s 11.11 Global Shopping Festival, which in 2018 reached $30.8 billion – in just 24 hours.

When we look at the penetration of eCommerce in the U.S. retail market, we see that, as disruptive as it has been, it is still only around 10% of the total American retail market. According to Andreessen Horowitz, this digital transformation has just begun, and it will continue to gather momentum and spread to other sectors over the coming years.
The Buyer’s Experience Affects eCommerce Success
Success in online business is increasingly driven by careful and continued attention to providing a good overall customer experience throughout the buyer journey. Customers want relevant information to guide their purchase decisions and allow them to be as independent as possible after they buy a product. This means sellers now need to provide much more content than they traditionally have.
Much of the customer journey today involves a buyer interacting independently with content related to the product of interest, and digital leaders understand that understanding the customer and providing content that really matters to them is a pre-requisite for digital transformation success.
B2B Buying Today is Omnichannel
In a recent study focused on B2B digital buying behavior that was presented at a recent Gartner conference, Brent Adamson pointed out that “Customers spend much more time doing research online – 27% of the overall purchase evaluation and research [time]. Independent online learning represents the single largest category of time-spend across the entire purchase journey.”
The proportion of time 750 surveyed customers making a large B2B purchase spent working directly with salespeople – both in person and online – was just 17% of their total purchase research and evaluation process time. This fractional time is further diluted when you spread this total sales person contact time across three or more vendors that are typically involved in a B2B purchase evaluation.
The research made evident that a huge portion of a sellers’ contact with customers happens through digital content, rather than in-person. This means that any B2B supplier without a coherent digital marketing strategy specifically designed to help buyers through the buyer journey will fall rapidly behind those who do.
The study also found that just because in-person contact begins, it doesn’t mean that online contact ends. Even after engaging suppliers’ sales reps in direct in-person conversations, customers simultaneously continue their digital buying journey, making use of both human and digital buying channels simultaneously.
Relevant Local Content Drives Online Engagement
Today it is very clear to digitally-savvy executives that providing content relevant to the buyer journey really matters and is a key factor in enabling digital online success. A separate research study by Forrester uncovered the following key findings:
- Product information is more important to the customer experience than any other type of information, including sales and marketing content.
- 82% of companies agree that content plays a critical role in achieving top-level business objectives.
- Companies lack the global tools and processes critical to delivering a continuous customer journey but are increasingly beginning to realize the importance of this.
- Many companies today struggle to handle the growing scale and pace of content demands.
Machine Translation Facilitates Multilingual Content Creation
This requirement for providing so much multilingual content presents a significant translation challenge for any enterprise that seeks to build momentum in new international markets. To address this challenge, eCommerce giants like eBay, Amazon, and Alibaba are among the largest users of machine translation in the world today. There is simply too much content needs to be multilingual to do this with traditional localization methods.
However, even with MT, the translation challenge is significant and requires deep expertise and competence to address. The skills needed to do this in an efficient and cost-effective manner are not easily acquired, and many B2B sellers are beginning to realize that they do not have these skill in-house and could not effectively develop them in a timely manner.
Expansion Opportunities in Foreign Markets
The projected future growth of eCommerce activity across the world suggests that the opportunity in non-English speaking markets is substantial, and any enterprise with aspirations to lead – or even participate – in the global market will need to make huge volumes of relevant content available to support their customers in these markets.
When we look at eCommerce penetration across the globe, we see that the U.S. is in the middle of the pack in terms of broad implementation. The leaders are the APAC countries, with China and South Korea having particularly strong momentum as shown below. You can see more details about the global eCommerce landscape in the SDL MT in eCommerce eBook.

The chart below, also from Andreessen Horowitz shows the shift in global spending power and suggests the need for an increasing focus on APAC and other regions outside of the US and Europe. The recent evidence of the power of eCommerce in China shows that these trends are already real today and are gathering momentum.
The Shifting Global Market Opportunity

To participate successfully in this new global opportunity, digital leaders must expand their online digital footprint and offer substantial amounts of relevant content in the target market language in order to provide an optimal local B2C and B2B buyer journey.
As Andreesen points out, the digital disruption caused by eCommerce has only just begun and the data suggests that the market opportunity is substantially greater for those who have a global perspective. SDL's MT in eCommerce eBook provides further details on how a digitally-savvy enterprise can handle the new global eCommerce content requirements in order to partake in the $40 trillion global eCommerce opportunity.

This is a slightly updated post that has been already published on the SDL site.
Happy Holidays to all.
May your holiday season be blessed and peaceful.
Click here to find the SDL eBook on MT and eCommerce.












{kind=link}
{kind=link}
{kind=link}