As the world moves increasingly to a “digital-first” approach across the business and government spectrum, it has become increasingly clear to any enterprise interested in reaching a larger digital population, that providing more multilingual content matters, and that the demand for more translated content will only grow, which also means that enterprise translation capabilities will need to be pervasive and scalable.

The challenge for globalization managers is further complicated by the increasing focus on customer experience (CX) which means that the content can vary greatly, in volume, velocity, and value to customers and internal stakeholders. All content does not need to go through traditional localization production and quality validation processes.
Content that is focused on understanding, communication, and listening does not require the same linguistic quality assurance, and in the digital space, user-generated and other external content is now often the most impactful content to consider.
Modern-era globalization managers need to understand what matters most to customers and balance their focus on the “mandatory” legally required content that localization has typically focused on, against the non-corporate content customers find most useful.
Though the value and business benefit of large-scale translation and localization are now well understood, globalization and localization managers tasked with making the global customer outreach happen, struggle with this objective.
They are faced with a fragmented, inconsistent, and fractured technology landscape and many sub-optimal tools currently exist in the language technology marketplace shown in the graphic below.

These tools are needed both to perform the many specific tasks involved in any globalization effort and to help establish structured processes that enable ongoing and emerging global customer-focused needs to be efficiently serviced.
Given the wide variety of tools and the diversity of the people needed to effectively execute the multiple globalization processes involved, straightforward and efficient data flow from sub-system to sub-system is desirable.
Successful globalization outcomes are often directly linked to enabling fast-flowing, unhindered data flows through a variety of translation-related processes. This is a necessary condition for success in a digital-first world.
However, what many Loc Buyers find is that some of the systems and tools they use impede and obstruct this smooth data flow, and thus the digital globalization initiative is often undermined and overly focused on repairing broken and problematic data flows.
If we look at the TMS part of the tech stack more closely, we can understand the challenge that globalization managers have when making long-term decisions on what their tech stack should look like. There are many choices, and identifying the specific characteristics of a superior system is not so clear.
We have learned that the best AI outcomes are driven by high-quality data above all else, and thus selecting technology that facilitates ongoing data access as technology changes, should be a prime concern and strategy for any forward-thinking globalization manager.

The critical technology components for most localization managers include the following categories:
1. CAT Tools used by translators
2. Translation Management Systems
3. Language Quality Assurance (LQA) Tools
4. Enterprise-capable MT
5. Audiovisual Translation tools are growing in importance
In general, it can be said that the better the integration between these key components is, the more successful the globalization outcomes and the more efficient the enterprise will be in providing a high-quality global customer experience.
Unfortunately, the reality for many localization teams is focused on repairing broken or non-existent connections between sub-systems, and building better data sharing between the various components in their back-end localization tech stack to power the customer-pleasing expanded multilingual CX.

Avoiding Lock-In with Proprietary Systems
As the enterprise matures in localization and globalization sophistication, it will likely develop and build valuable linguistic assets over time. These linguistic assets need to be easily accessed and available to be shared with emerging new tools and platforms that provide business leverage, powered by new AI capabilities, as customer needs and CX imperatives dictate.
The tech stack complexity challenge for globalization managers is further exacerbated by the fact that much of the technology is still evolving.
Thus, any technology component that creates lock-in and prevents the straightforward transfer of linguistic assets to new superior language technology tools or platforms as they become available IS TO BE AVOIDED.
These siloed systems create what is called Tech Debt. This refers to the off-balance-sheet accumulation of all the technology work a company needs to do in the future. Tech debt results from software entropy and a lack of integration between different systems and data.
And it’s not just a minor inconvenience. A majority of businesses say that tech debt is slowing their pace of development, and resulting in real-world losses in sales and productivity.
Tech debt can produce several negative consequences for businesses:
- 66% say tech debt causes bugs, errors, outages, and other quality issues
- 63% say tech debt is slowing the pace of development
- 33% of engineers’ time is spent dealing with tech debt—about 13.5 hours in an average work week
- 10-20% of the technology budget dedicated to new products is diverted to resolving issues related to tech debt
The benefits of reducing tech debt are also significant and include:
- 50% faster service delivery times for the business
- 200% increase in productivity
- Significant savings from reduced maintenance spend on existing software
Buyers should demand that enabling straightforward API access to client linguistic data without restriction or restraint should be a basic and critical requirement for any modern enterprise software solution or TMS.
Sophisticated new capabilities emerging from NLP research in Large Language Models, Responsive MT, and other emerging Language AI research will be almost useless to those companies that cannot quickly move relevant enterprise linguistic data to these new applications. They will be unable to properly explore possibilities of providing better CX with emerging linguistic AI capabilities.
This data lock-in is especially true for some of the current TMS systems that create multiple layers of technical, and even legal obstacles to straightforward data sharing. These obstacles invariably trap some Loc Buyers into sub-optimal workflows and solutions.
It is surprising that more Loc Buyers do not understand the importance of free and easy access to all linguistic data over the long-term, and suggests that Loc Buyers are extremely naïve in terms of making technology evaluations and selections that stand the test of time.
Sub-optimal initial choices will require regular overhauls in the technology stack to overcome obstacles created by proprietary lock-in technology.
Data is the lifeblood of any organization and the backbone that supports the creation of market-leading CX. The AI-driven world of tomorrow will be increasingly data-driven.
However, it is nearly impossible to make this data actionable in marketing activations and other business processes without data centrality and shareability. To avoid this, globalization managers should look for partners who can help them democratize their data sets so that they’re integrated and accessible by all.
The Growing Importance of Integration with Enterprise IT
Translation technology has reached an inflection point, as translation connects to the major trends affecting every industry: big data, cloud computing, and artificial intelligence (AI). Language platforms that can scale from millions to billions of words of translated content per month are being created as enterprise buyers and innovative language service providers seek to align their language systems with the technology stacks of globally focused enterprises.
Implementing many different systems and sources that don’t speak to each other will make it harder for the business to enact data-backed decisions and integrate with core IT functionality. Straightforward integration with core enterprise IT is a key requirement to enable successful global CX outcomes.
The ability to quickly import, clean, and use data from countless sources is critical to marketers and globalization managers, but rarely easy.
One of the barriers to realizing this data actionability stems from rigid data structures that can’t onboard, transport, and unify both structured and unstructured data from different sources. Flexible data architecture and a scalable hygiene framework can speed up the timeline for data activation and value creation.

The chart above shows the relationship between translation quality and content volume. It also shows that the highest returns on investments in translation technology will come from those areas focused on global CX and eCommerce.
The collaboration between localization teams and enterprise IT teams are growing in sophistication and now increasingly both internal corporate data and external data from social media and customer reviews are being mingled and merged to provide better CX.
This often requires handling large volumes of user-generated content (UGC) and monitoring social media brand impressions which are so voluminous that traditional localization workflows are not valid.
UGC is a dominant element of the eCommerce content landscape and even presents special challenges for MT technology. UGC content is often written by non-native speakers and, most likely, by non-professional content writers and thus needs specialized treatment and a different approach from typical localization content. But we see today that global market leaders learn to do this at scale, with new techniques that assume and drive evolutionary quality improvements.
Tech-savvy localization managers who understand this “start now and improve gradually approach“ on massive content volumes are now being seen as vital partners in global growth strategies. Best practices suggest that the most effective strategy is to have MT and Human translators working together to build a continuous improvement cycle.
The strategy to translate a billion new words across multiple use cases every month has to be different than a typical localization translate-edit-proof (TEP) process. This is made difficult or even impossible with TMS systems that do not allow easy access to ALL linguistic assets.

Airbnb is an example of emerging localization leadership where the localization team is seen as a vital partner in enabling global growth and works closely with IT, Legal, and Product teams to deliver better global customer experiences.
The Airbnb localization team oversees both typical localization content and user-generated content (UGC), across the organization, which means they oversee billions of words a month being translated across 60+ languages using a combined human plus continuously improving MT translation model. The localization team enables Airbnb to translate customer-related content across the organization at scale. High-value external content is often given the same attention as internally produced marketing content.
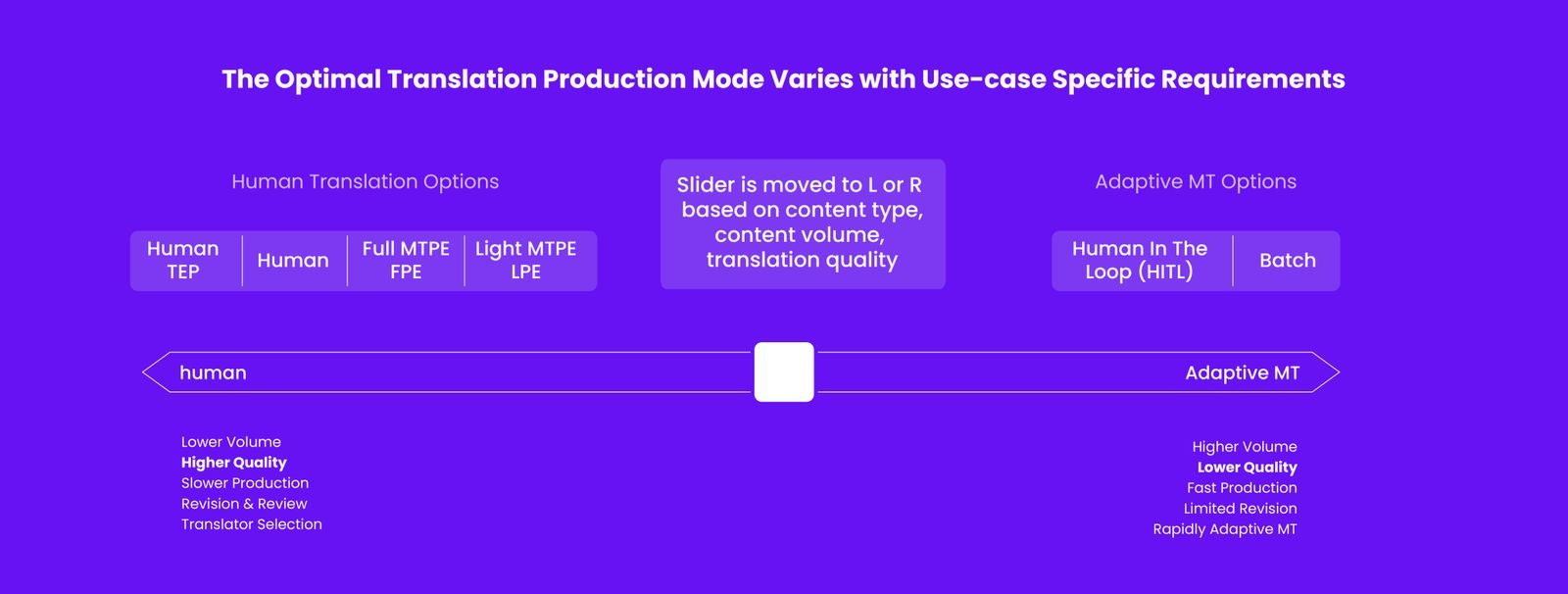
When dealing with CX-focused translation scenarios, the business requirements direct globalization managers to focus on optimizing the translation production mode to the volume, speed, quality requirements, and the value of the content to customers.
This is a clear shift away from the traditional LQA-focused localization workflows where TMS systems have traditionally been useful.

TMS systems have been most useful in relatively low-volume, complex workflows that involve multiple levels of human touch on the translated content. This is the top left-hand corner of the chart above. TMS systems add little to no value in scenarios with high volume fast flowing CX data where data flow straight from MT to dissemination.
Dated monolithic translation management systems (TMS) are giving way to micro-service and cloud-based architectures, with machine learning driving systems toward enterprise-scale automation where speed, scale, and the value of the content to the global customer matter more than achieving perfect linguistic quality.
Thus, increasingly we see that TMS systems are completely bypassed or irrelevant, and there is greater use of “raw MT” or carefully pre-tuned MT rather than fully post-edited MT.

The Emerging Requirements for a Language Platform
As more senior executives in the global enterprise ask questions like:
- How do we integrate our international strategy with our overall corporate strategy?
- What will this take in terms of people, process, and technology?
We should expect a shift to language as a feature at the platform level wherein language is designed, delivered, and optimized as a feature of a product and/or service from the beginning.
Language accessibility is integrated into content and procedural workflows that affect almost everyone within the organization at some point. Something that analysts call a "language platform."
Rebecca Ray of CSA describes the impact of producing relevant content for modern eCommerce marketplaces at scale and touches upon the key requirements of a Language Platform.
The success of globalization leaders like Airbnb demonstrates the value of developing comprehensive and collaborative capabilities with a more globally embedded and pervasive translation-focused ecosystem. The Airbnb deployment is a pioneering example in global CX best practice that shows how extensive and deep-reaching translation workflows can be integrated into corporate IT when the value is understood at executive levels.
A CX-focused and capable Language Platform that is ready for digital-first globalization and localization challenges would need all of the following key components working together in a highly integrated and seamless manner.
- Essential TMS capabilities to monitor translation projects, and linguistic quality, and generate and manage critical translation workflows for different content types as needed.
- An adaptive and continuously improving MT system that automates personalization and performance optimization for each enterprise customer and manages the collection of corrective feedback across dozens of enterprise use cases. This element is increasingly becoming the most important element of the back-end tech stack and the heart of the Translation Engine to provide superior global CX.
- Computer-assisted translation (CAT) tools to enhance translator productivity, simplify project management, and share corporate linguistic assets like translation memories (TMs), glossaries, and terminology. In the modern era, CAT tools would also need to handle video, audio, and other social media-focused multimedia data.
- Open and service-based architecture to allow continuing evolution of translation processes and addition of new core functions powered by machine learning with speed and agility. Linguistic assets are maintained in a continuously leverageable state so that these assets can be connected to emerging linguistic AI technology without hindrance or restraint.
- Connectors: As the need for an Enterprise Translation Engine becomes more apparent the Language Platform will need to connect to CMS, Marketing Automation, Customer Data Platforms (CDP), CRM, ERP, Messaging, and Customer Support & CX platforms, in addition to leading social media to listen to and monitor customer conversations.
Look for a partner rather than a vendor, that can help you simplify and rationalize your tech stack and the increasing amounts of data you’re ingesting. Instead of logging in to different systems repeatedly according to content type and purpose, look for a vendor who can consolidate these into one simplified view. Additionally, ensure that data can be shared across vendors in this centralized hub so that you can leverage the power of these insights across the scope of your audience.
The Translated Tech Stack
TranslationOS is a hyper-scalable translation platform, that directly connects clients with translators that also provides management access to translation-related KPIs. It also provides the technical foundations to build a next-generation Language Platform. It provides customizable dashboards that give globalization managers access to KPIs, project status, quality performance, and linguist profiles.
TranslationOS is a technology platform that allows straightforward access to client data whenever it is required for other downstream applications, or just for internal archival purposes. Client linguistic assets always remain within easy reach of the client's developers to support other valued added processes that can arise over time.
TranslationOS is also the overarching technology that tightly ties together enterprise translation memory, adaptive MT and corrective feedback management, CAT, and multimedia data management tools.
TranslationOS has a growing set of content connectors enabling external data ingestion and export to enterprise IT infrastructure.
TranslationOS includes an AI-driven translator matching tool (T-Rank) to ensure optimal selection from a qualified, and continuously verified pool of 400,000 translators for different projects using 30+ factors (e.g., availability, historical performance, subject matter experience, qualifications) to drive objective rankings to ensure the identification of the best-suited resources.
ModernMT is an adaptive MT system that is highly flexible, responsive, easy to manage and maintain, continuously learning, and able to incorporate ongoing human corrective feedback to ensure better MT output.
It consistently shows up as a top-performing MT system in independent third-party MT quality evaluations even before it has been adapted and tuned to specific enterprise content. It seamlessly integrates into TranslationOS and leading CAT tools like MateCat, Trados, and MemoQ.
In 2022 it has also been integrated with MateSub and MateDub to enable the automated translation of corporate multimedia content.
MateCat is a free, open-source, performance-oriented online CAT tool that allows translators to easily share TMs, and glossaries and interact dynamically with ModernMT to ensure continuously improving MT suggestions. It is integrated with MyMemory, a massive, yet clean TM gathered over 20 years, to augment and increase TM matching possibilities.
MateSub is a CAT tool optimized for subtitling tasks. It combines state-of-the-art AI (auto-spotting, auto-transcription, auto-translation) with a powerful and easy-to-use editor to let you create higher quality subtitles, dramatically faster.
MateDub is an AI-powered tool to assist in voice-over dubbing projects which can add digital voices synthesized from human voice-actor sampling. It allows users to dub videos by simply editing text.

We are going to see much more focus and discussion on Language Platforms, Translation Layers, and Translation Operating Systems for fast-flowing CX-related data that are also built on much more open, new integrations-friendly, and transparent technology stacks.









