As we have seen from several posts recently, understanding the quality of your MT output at different points in the process is a key to success with the technology. The more precise your assessment and ability to measure this, the more effective your use experience. The range of quality assessment methodologies can vary from the laborious and expensive TAUS DQF to the minimalist and easy-to-do-wrong BLEU scores. They all have a place once you know what you are doing.
MT practitioners must find rapid but accurate ways to assess the quality of the MT output they are creating. This assessment determines all of the following:
It is useful and timely to use the US presidential elections to illustrate this. You have to understand your data to poll (or sample) intelligently. So an MT practitioner who only samples (or polls) 10,000 voters (or segments) in Texas or New York will conclude something erroneous and different from somebody who polls 10,000 Voters (or segments) across Florida, NC, NV, PA and OH. The conclusions from this second sample are more likely to represent the overall outcome of the whole population. In MT we are always trying to assess what the quality of 10 million (or some large number = the population) segments is by sampling 5,000 or 10,000 segments. This assessment can only be as good as your sampling. This is why it really matters that you understand your data as all your conclusions and most of your results will depend on that.

This post was written by Poulomi Choudhury পৌলোমী চৌধুরী of KantanMT. There are at least 3 ways I know to transliterate her name in English so it is useful to have it in an Indian script.
Traditionally, language quality review for MT involves the Project Managers (PMs) sending copies of a static spreadsheet to a team of translators. This spreadsheet contains lines of source and target segments, with additional columns where the reviewers score the translated segments per set parameters.
Once the spreadsheets are sent to the reviewers, PMs are left completely in the dark. They have no idea of the state of the reviewers’ progress or have a sense for when they might complete the review, or if they have even started the project.
If that sounds tiring, imagine what the PM must go through!
We have listed 5 ways in which you can reduce your frustration and get the best out of the MT language quality review process.
Identify what you want to get out of your translated content – what is the purpose of your content? Setting very specific parameters, for e.g., capitalisations, spacing, etc. for your reviewers, based on the context of your translation will help streamline the review process. These are the Key Performance Indicators (KPIs), against which the MT output can be scored and assessed.
The more specific the KPIs are, the more nuanced your assessment will be. We at KantanMT have found that KPIs based on the Multidimensional Quality Metrics (MQM) standards enable flexible and high-quality language quality review.

The trick to ensuring that reviewers give feedback for each parameter before moving on to a new segment is to send them specific and strict reminders or notifications about the mandatory fields, before each new project. Some automated language quality review tools can remind reviewers to enter their score and feedback for incomplete fields before they can progress to the next segment. However, if you are stuck with Excel, setting up Macros to make the fields mandatory can be helpful.

Say for example, if you want the translated text to be in a gender-neutral language, even though the source and target languages allow for gendered pronouns; you could add this as a KPI for your reviewers. Or, you could add KPIs for issues related to specific ‘offensive’ content. As an example: An American text uses the “OK” symbol (👌) to indicate approval, but this symbol is considered offensive in Brazil.
Once again, it is important to specify if these unique stylistic preferences are mandatory fields for your reviewers.




KantanLQR
At KantanMT, we developed KantanLQR, a Language Quality Review (LQR) tool to formalise the evaluation of translation quality of KantanMT engine output. It automates some of the language quality review processes mentioned in this article. It is an online quality review tool designed for both Project Managers and Reviewers, and helps them collaborate on an LQR project, without the need of countless emails and spreadsheets!
KantanLQR helps the PM monitor and track the progress of LQR projects in real time, with instant and highly visual reports. This means that unlike traditional LQR process with Excel, the PMs are no longer in the dark – they can view the overall quality of an MT engine, and even stop the review process if they find that the engines have reached the desired quality, and are ready to go live.

KantanLQR also enables the PM to set up custom KPIs or select existing KPIs, based on the MQM Framework. Custom KPIs are especially useful when the LQR project needs to allow for unique stylistic, cultural or organisational preferences. PMs can even make some of these KPIs mandatory, ensuring that reviewers complete all fields before moving to the next segment.


=================================
This article was previously published on the KantanMT blog and has been republished here with modifications by Poulomi Choudhury. You can get more information on the KantanMT products at https://www.kantanmt.com
 Poulomi Choudhury is a content and marketing strategist at KantanMT. Her primary interest lies in literature, language and cultural investigation, and the intersectionality and application of these themes in the contemporary business world. She holds an M.Phil. in Popular Literature from Trinity College Dublin and speaks English, Bengali and Hindi.
Poulomi Choudhury is a content and marketing strategist at KantanMT. Her primary interest lies in literature, language and cultural investigation, and the intersectionality and application of these themes in the contemporary business world. She holds an M.Phil. in Popular Literature from Trinity College Dublin and speaks English, Bengali and Hindi.
MT practitioners must find rapid but accurate ways to assess the quality of the MT output they are creating. This assessment determines all of the following:
- How much effort is needed to get the output to a defined level of acceptability?
- How much to pay post-editors given the very specific output an engine produces?
- How much additional work will be needed to deploy an engine in a production environment?
- What level of certainty do we have in meeting delivery deadlines given the current quality levels?
It is useful and timely to use the US presidential elections to illustrate this. You have to understand your data to poll (or sample) intelligently. So an MT practitioner who only samples (or polls) 10,000 voters (or segments) in Texas or New York will conclude something erroneous and different from somebody who polls 10,000 Voters (or segments) across Florida, NC, NV, PA and OH. The conclusions from this second sample are more likely to represent the overall outcome of the whole population. In MT we are always trying to assess what the quality of 10 million (or some large number = the population) segments is by sampling 5,000 or 10,000 segments. This assessment can only be as good as your sampling. This is why it really matters that you understand your data as all your conclusions and most of your results will depend on that.
This post was written by Poulomi Choudhury পৌলোমী চৌধুরী of KantanMT. There are at least 3 ways I know to transliterate her name in English so it is useful to have it in an Indian script.
-------------------
You have your finger on the pulse of the latest technologies, and you are proud to be using the latest automated technology for your localization needs. But, sometimes it might feel that you are still stuck in the 90s when it comes to reviewing your Machine Translation (MT) output for quality - especially if you are using spreadsheets to collate your reviewers’ feedback on segments.Traditionally, language quality review for MT involves the Project Managers (PMs) sending copies of a static spreadsheet to a team of translators. This spreadsheet contains lines of source and target segments, with additional columns where the reviewers score the translated segments per set parameters.
Once the spreadsheets are sent to the reviewers, PMs are left completely in the dark. They have no idea of the state of the reviewers’ progress or have a sense for when they might complete the review, or if they have even started the project.
If that sounds tiring, imagine what the PM must go through!
We have listed 5 ways in which you can reduce your frustration and get the best out of the MT language quality review process.
1. Set exact parameters for reviewers
This may sound like an obvious one, but you’d be surprised at how often project timelines are delayed because reviewers did not receive clear, precise and exact review parameters at the beginning of the project.Identify what you want to get out of your translated content – what is the purpose of your content? Setting very specific parameters, for e.g., capitalisations, spacing, etc. for your reviewers, based on the context of your translation will help streamline the review process. These are the Key Performance Indicators (KPIs), against which the MT output can be scored and assessed.
The more specific the KPIs are, the more nuanced your assessment will be. We at KantanMT have found that KPIs based on the Multidimensional Quality Metrics (MQM) standards enable flexible and high-quality language quality review.

Figure 1: Some typical language quality review parameters for MT projects
2. Collect reviewer feedback
Setting specific project parameters or KPIs for your reviewers is great. But sometimes reviewers may unintentionally skip entering the score for some of the parameters. This creates a gap, which can affect the quality of the MT engine you are building.The trick to ensuring that reviewers give feedback for each parameter before moving on to a new segment is to send them specific and strict reminders or notifications about the mandatory fields, before each new project. Some automated language quality review tools can remind reviewers to enter their score and feedback for incomplete fields before they can progress to the next segment. However, if you are stuck with Excel, setting up Macros to make the fields mandatory can be helpful.

Figure 2: Shows review instructions in MS Excel
3. Mention any unique stylistic preferences for your business
Each translation project is unique, and so, a set number of pre-defined KPIs may not be enough for every project. Which is why it is nice to be able to add new KPIs to a project. This means that if the text requires some unique stylistic translation, your reviewers will be able to score the content based on those new sets of KPIs.Say for example, if you want the translated text to be in a gender-neutral language, even though the source and target languages allow for gendered pronouns; you could add this as a KPI for your reviewers. Or, you could add KPIs for issues related to specific ‘offensive’ content. As an example: An American text uses the “OK” symbol (👌) to indicate approval, but this symbol is considered offensive in Brazil.
Once again, it is important to specify if these unique stylistic preferences are mandatory fields for your reviewers.

Figure 3a: Translation quality KPIs (Image: http://www.qt21.eu/)

Figure 3b: Example of a specific stylistic preference in the MQM Framework. A project may have stylistic preferences that do not fall within any category in the MQM Framework; these should be custom added to the project separately
4. Provide reviewers with sample translations
Having a few example texts of what you expect the reviewers to look out for in the translation will help to speed up the process. Even a few thousand words (100 segments) would be enough for the reviewers to understand what is expected from the LQR project, and this will help them to progress with greater confidence.5. Provide reviewers with your corporate style guidelines
Your corporate brand and style guide is the end-all-and-be-all for all your corporate communications. You can help your reviewers to know about your organisation and product, and your customers better by giving them a copy of your brand and style guide. This, in turn, will help them review your MT output in a more nuanced fashion.
Figure 5a: A typical corporate style guideline, which should be given to reviewers so that they have a better understanding of the project requirement.

Figure 5b: Reviewers can use the corporate brand and style guideline to review the stylistic issues during language quality review (Image: http://www.qt21.eu/)
KantanLQR
At KantanMT, we developed KantanLQR, a Language Quality Review (LQR) tool to formalise the evaluation of translation quality of KantanMT engine output. It automates some of the language quality review processes mentioned in this article. It is an online quality review tool designed for both Project Managers and Reviewers, and helps them collaborate on an LQR project, without the need of countless emails and spreadsheets!
KantanLQR helps the PM monitor and track the progress of LQR projects in real time, with instant and highly visual reports. This means that unlike traditional LQR process with Excel, the PMs are no longer in the dark – they can view the overall quality of an MT engine, and even stop the review process if they find that the engines have reached the desired quality, and are ready to go live.

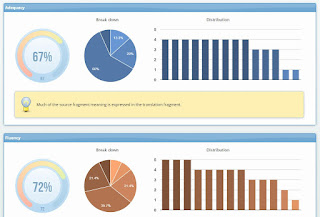
Figure 6a: High-level view of the progress of an LQR project. In this example: Adequacy and Fluency
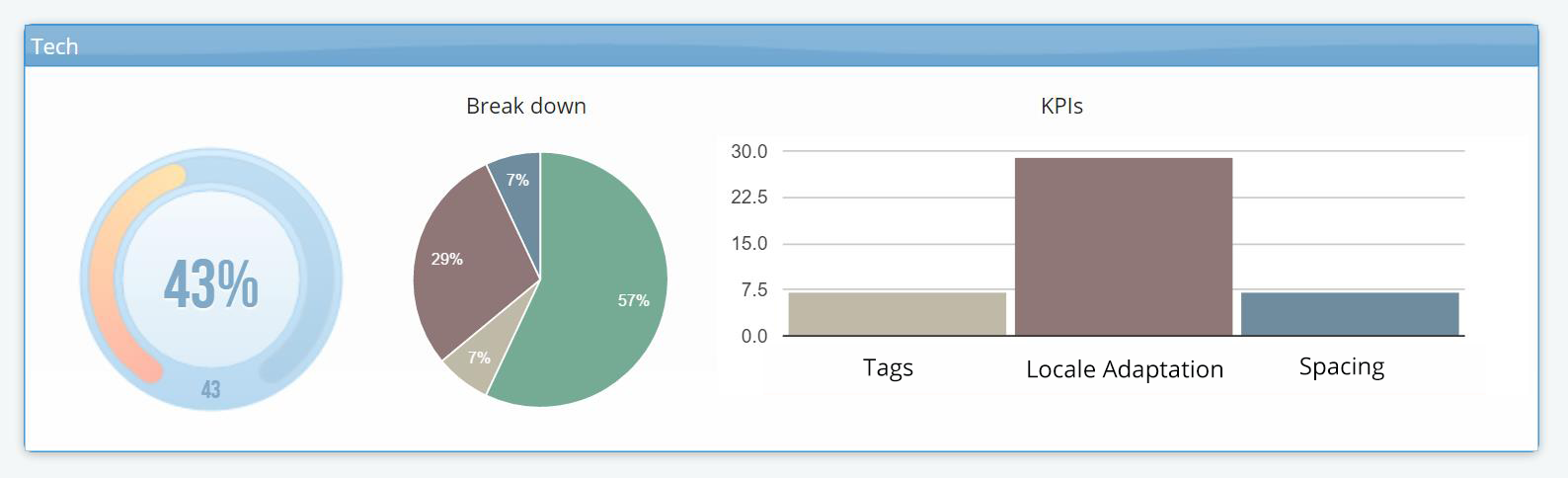
Figure 6b: Granular level KantanLQR report for error typologies
KantanLQR also enables the PM to set up custom KPIs or select existing KPIs, based on the MQM Framework. Custom KPIs are especially useful when the LQR project needs to allow for unique stylistic, cultural or organisational preferences. PMs can even make some of these KPIs mandatory, ensuring that reviewers complete all fields before moving to the next segment.

Figure 6c: Project Manager view of Key Performance Indicators

Figure 6d: Reviewer view of segments and KPIs
=================================
This article was previously published on the KantanMT blog and has been republished here with modifications by Poulomi Choudhury. You can get more information on the KantanMT products at https://www.kantanmt.com

HI Luigi, I absolutely understand where you are coming from. When it comes to the application of the QT21 model, it is indeed easier said than done. And while it is okay to say that "exact parameters" should be set, it also involves a lot of planning and a big enough learning curve.
ReplyDeleteAt KantanMT, we recognise the inherent challenges in the MQM standard (which is the parental guardian of DQF framework too). However, we also think it's a very flexible framework from which you can select what factors suit your measurement of quality. Additionally, you're not obligated to use the entire standard. You can pick and choose what suits both the timeframe you're working with and the depth in which you want to measure quality.
With KantanLQR, we have tried to make this process even simpler. While the KantanLQR platform fully supports the factors defined within the MQM standard, we're also created a simplified default set of factors that are easier to work with, less time consuming to deploy operationally and far simpler to understand and analyse. These simplified factors makes for easier measurements of translation quality and analyse of how an engine is performing.
In fact, if you would like to see how the these are set up and organised, we would be very happy to show you a demo.
I look forward to your thoughts.
Poulomi