Artificial Intelligence and Machine Learning have been all over the news of late, and we see that all the internet giants are making huge investments in acquiring AI expertise and/or using "machine intelligence" which is the term being used when describing how these two areas come together in business applications. It is said that AI is attracting more venture capital investment than any other single area in VC at the moment, and there are now people regularly claiming that the AI guided machines will dominate or at least deeply influence and transform much of our lives in future perhaps dangerously so. This overview of AI and this detailed overview of Neuralink is quite entertaining and gives one a sense of the velocity of learning, and knowledge acquisition and transmission that we are currently facing and IMO are worth skimming through at least.
However. machines learn from data and find ways to leverage patterns in data in innumerable ways. The value of this pattern learning can only be as good as the data used and however exciting all this technology seems we need to understand that our comprehension of how the brain (much less the mind) works, is still really is only in its infancy. “Machine learning” is a fancy way of saying “finding patterns in data”. The comparative learning capacity and neuroplasticity of any 2-year-old child will put pretty much put all of these "amazing and astounding" new AI technologies to shame. Computers can process huge amounts of data in seconds, and sometimes they can do this in VERY useful ways, and most AI is rarely if ever much more than this. If the data is not good, the patterns will be suspect and often wrong. And given what we know about how easy it is to screw data up this will continue to be a challenge. This will not change no matter how good the algorithms and technology are. The importance of data quality has been and will continue to be a major challenge for AI that learns from biased language data and several have pointed out how training on racially and gender biased data will propagate through machine learning.
The business translation industry is only just beginning to get into an understanding of the value of "big data". Very few actually collect data at a level that they can really leverage these new options. I have seen that the industry has terrible and archaic practices with translation data organization, management and collection in my years working with SMT where LSPs struggle to find data to build engines. A huge amount of time is spent on gathering data in these cases, and little is known about its quality and value. However, as this post points out there is a huge opportunity in gathering all kinds of translation process related data, and leveraging it by properly cataloging and organizing it, so that most man-machine processes improve and continually raise productivity and quality.
This is a guest post by Danny de Wit about a cloud-based technology he has developed called Tolq. This is an AI infused translation management system with multiple translation processes that can be continually enhanced with AI-based techniques as process related data is acquired. The system is a combination of TMS, project management and CAT tool functionality that can continually be updated and enhanced to improve workflow ease and efficiency for both traditional and MT-related workflows. Thank you to Mila Golovine for introducing me to Danny.
Boom. There it was in the news: Google NMT makes all LSP's redundant with their Neural Machine Translation efforts! And if not now, then surely within a few years. Neural machine translation solves it when it comes to translation. Right?i
Translation industry insiders already know this is not the case, nor is it going to be the case soon. Translation is about understanding, and not just about figuring out patterns, which neural networks do so well. So there are still huge limitations to overcome: homonyms, misspelled source words, consistency, style and tone-of-voice, localisation, jargon/terminology, incorrect grammar in the source text and much more.
For now, artificial intelligence is a tool. Just like translation memory and cat tools are. But it's important to understand that this is a very powerful one and one of a different kind. This is a tool, which when applied correctly, gains strength every day and will open up more and more new opportunities.
Within a period of just a few years, the entire translation industry will be reshaped. Translation is not the only industry where the impact will be felt. The same will go for virtually any industry. The technology is that powerful. But it won’t be in the shape of zero-shot NMT.
Artificial intelligence is a wave of innovation that you have to jump on. And do so today.
Fortunately, it turns out that one key thing to help you do this is one that LSP's have been doing already for years: collecting high-quality data.
All A.I. advancements are built upon models that are generated from data-sets. Without data, there is no model. Data is both the enabler, but also the limit. What's not in the data, is not available to be used.
LSP's have been collecting data for years and years. Using that data to power A.I. algorithms today and in the future is a key strategy to implement.
In addition, LSP's have client specific data and add to that data on a daily basis. This means there's the opportunity to have client specific A.I. tools that gain in strength over time. Offering this to your clients is a big differentiator.
Having generic NMT plus different layers of client specific NMT and other client specific A.I. tools can provide you with workflows that were previously unachievable.
But how do you integrate this inside your operations? We all know that clients and therefore LSP's have a hard time managing data. The incentive to centralise was always there, but it has never been as clear or impactful as it is right now.

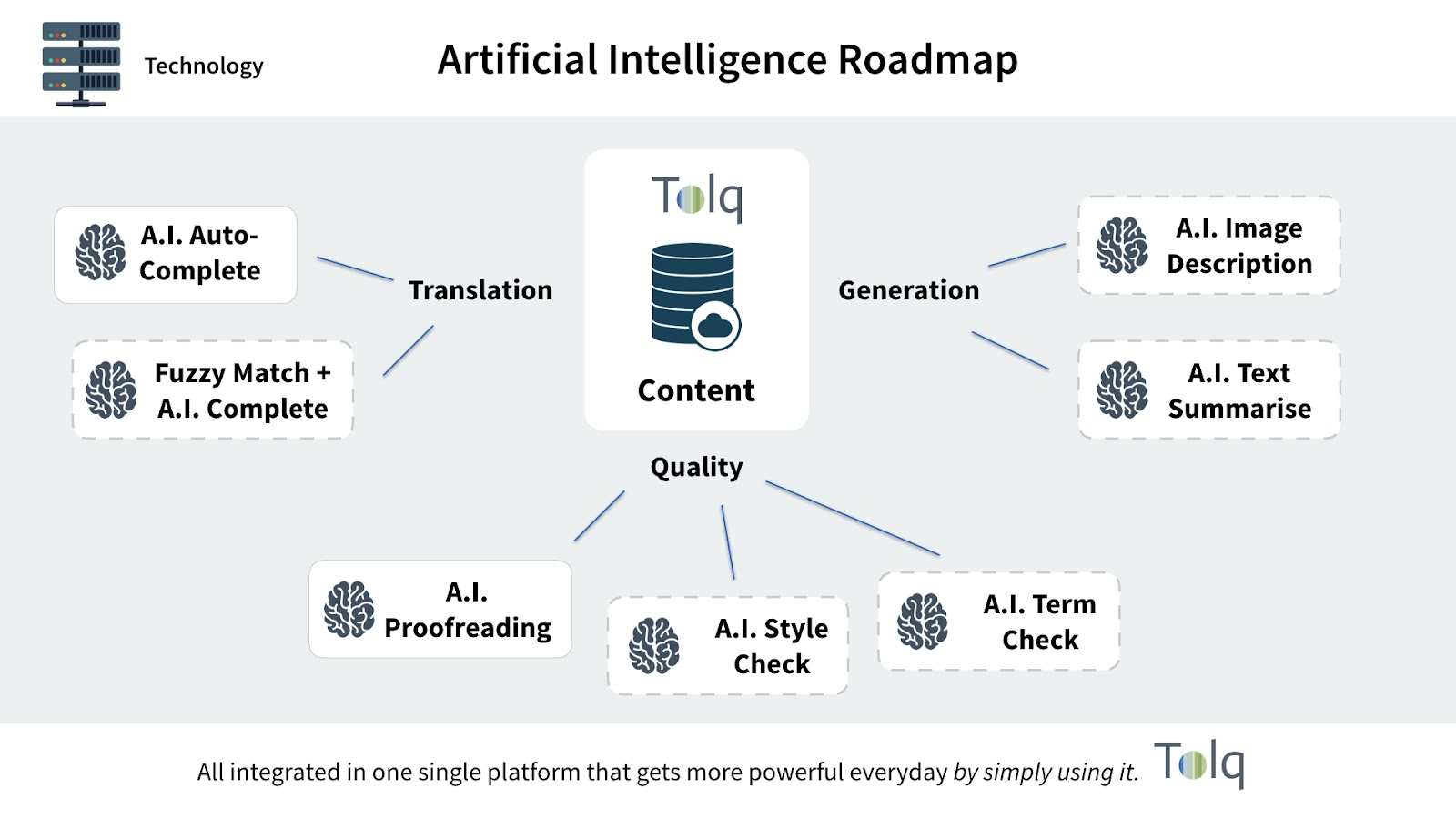
What can other advances should we expect from A.I. in the near term?
LSP's can look forward to more advances for workflow optimisation and the possibility to introduce new services.
The generic engines will be one of the tools to take advantage of, but to get to the final product that clients require, LSP's that centralise their operations and data will be able to take advantage of new algorithms to offer clients new services. Some examples are shown in the diagram below. But many more will be made available as the A.I. wave increases in speed.
When it comes to creating value the core strategy for LSP's should be to start combining technology with data. Even the technology giants will be envious of that combination. We expect to see huge acquisitions in that space.
In addition, combining data with algorithms can provide powerful scalable profit centers due to their nature. It's data crunching vs. human workflows.

However. machines learn from data and find ways to leverage patterns in data in innumerable ways. The value of this pattern learning can only be as good as the data used and however exciting all this technology seems we need to understand that our comprehension of how the brain (much less the mind) works, is still really is only in its infancy. “Machine learning” is a fancy way of saying “finding patterns in data”. The comparative learning capacity and neuroplasticity of any 2-year-old child will put pretty much put all of these "amazing and astounding" new AI technologies to shame. Computers can process huge amounts of data in seconds, and sometimes they can do this in VERY useful ways, and most AI is rarely if ever much more than this. If the data is not good, the patterns will be suspect and often wrong. And given what we know about how easy it is to screw data up this will continue to be a challenge. This will not change no matter how good the algorithms and technology are. The importance of data quality has been and will continue to be a major challenge for AI that learns from biased language data and several have pointed out how training on racially and gender biased data will propagate through machine learning.
The business translation industry is only just beginning to get into an understanding of the value of "big data". Very few actually collect data at a level that they can really leverage these new options. I have seen that the industry has terrible and archaic practices with translation data organization, management and collection in my years working with SMT where LSPs struggle to find data to build engines. A huge amount of time is spent on gathering data in these cases, and little is known about its quality and value. However, as this post points out there is a huge opportunity in gathering all kinds of translation process related data, and leveraging it by properly cataloging and organizing it, so that most man-machine processes improve and continually raise productivity and quality.
This is a guest post by Danny de Wit about a cloud-based technology he has developed called Tolq. This is an AI infused translation management system with multiple translation processes that can be continually enhanced with AI-based techniques as process related data is acquired. The system is a combination of TMS, project management and CAT tool functionality that can continually be updated and enhanced to improve workflow ease and efficiency for both traditional and MT-related workflows. Thank you to Mila Golovine for introducing me to Danny.
====================
Boom. There it was in the news: Google NMT makes all LSP's redundant with their Neural Machine Translation efforts! And if not now, then surely within a few years. Neural machine translation solves it when it comes to translation. Right?i
Translation industry insiders already know this is not the case, nor is it going to be the case soon. Translation is about understanding, and not just about figuring out patterns, which neural networks do so well. So there are still huge limitations to overcome: homonyms, misspelled source words, consistency, style and tone-of-voice, localisation, jargon/terminology, incorrect grammar in the source text and much more.
For now, artificial intelligence is a tool. Just like translation memory and cat tools are. But it's important to understand that this is a very powerful one and one of a different kind. This is a tool, which when applied correctly, gains strength every day and will open up more and more new opportunities.
Within a period of just a few years, the entire translation industry will be reshaped. Translation is not the only industry where the impact will be felt. The same will go for virtually any industry. The technology is that powerful. But it won’t be in the shape of zero-shot NMT.
Artificial intelligence is a wave of innovation that you have to jump on. And do so today.
Fortunately, it turns out that one key thing to help you do this is one that LSP's have been doing already for years: collecting high-quality data.
The Key is Data & Algorithms
All A.I. advancements are built upon models that are generated from data-sets. Without data, there is no model. Data is both the enabler, but also the limit. What's not in the data, is not available to be used.
LSP's have been collecting data for years and years. Using that data to power A.I. algorithms today and in the future is a key strategy to implement.
In addition, LSP's have client specific data and add to that data on a daily basis. This means there's the opportunity to have client specific A.I. tools that gain in strength over time. Offering this to your clients is a big differentiator.
Having generic NMT plus different layers of client specific NMT and other client specific A.I. tools can provide you with workflows that were previously unachievable.
But how do you integrate this inside your operations? We all know that clients and therefore LSP's have a hard time managing data. The incentive to centralise was always there, but it has never been as clear or impactful as it is right now.
Unification of Workflow, Data Storage and Algorithms: the new holy trinity for LSP's
The interests of LSP's and clients are aligned where it comes to the unification of these elements.
Clients can take advantage of huge cost savings and new services (like generated multi-lingual content a.o.).
LSP's will operate more efficiently and gain huge workflow management advantages.
LSP's increase on their position as indispensable partners for clients, because of the complexity of the technology involved. Clients will not be able to implement anything like this themselves. In part due to the data + algorithms requirement to make this all work.
Simple workflow improvements, that companies like recently Lilt offer are a step forward, but due to their architecture can only add some efficiency gains inside an existing process, but not lift the LSP organisation to a new level taking advantage of all A.I. has to offer.
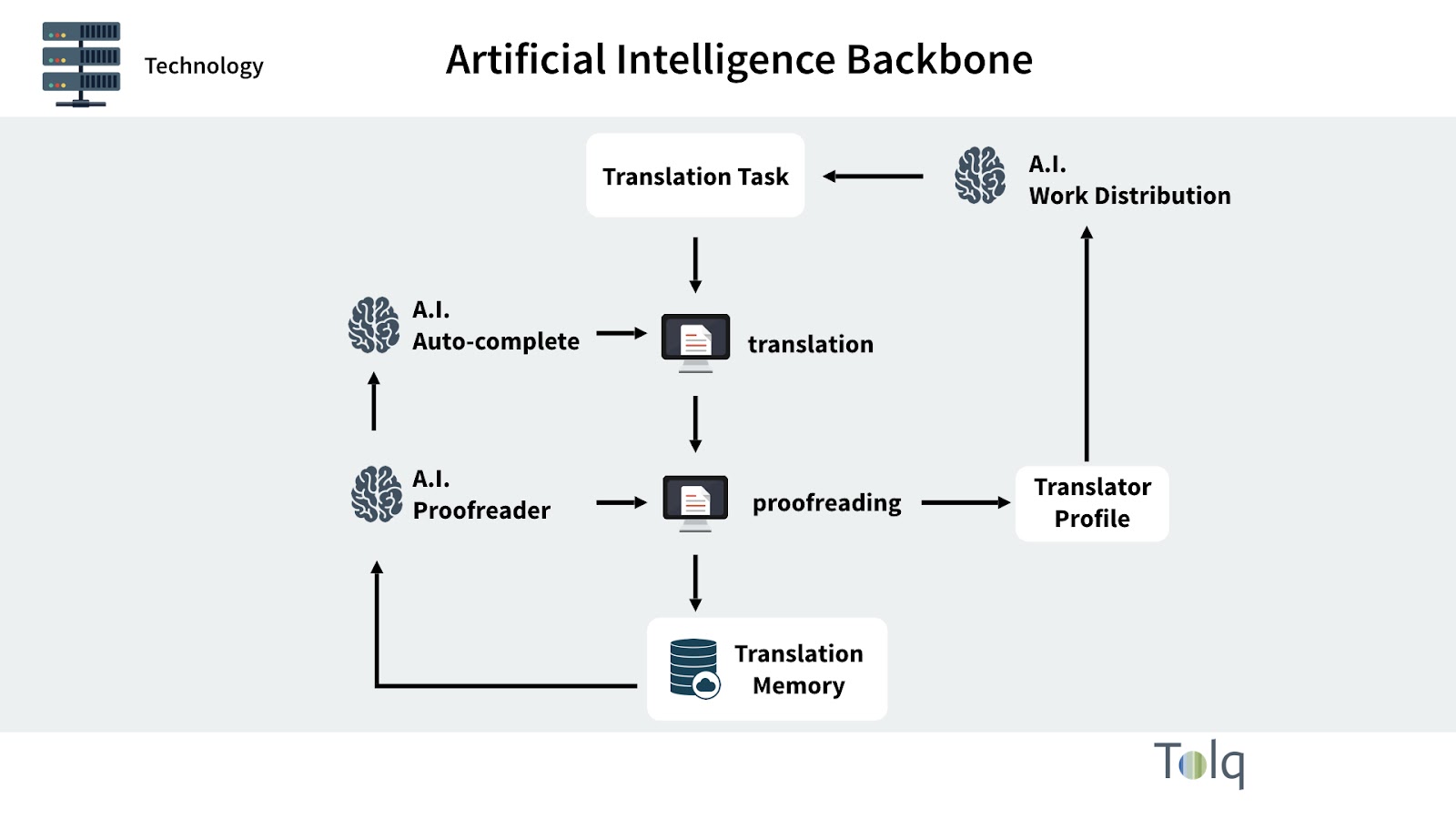
Instead, architecture that brings together the three key elements to take full advantage of the future is a much better alternative. Tolq calls this the "A.I. Backbone" which is present in all our operations. Unifying all workflows and data storage to a central, but still layered, structure. Then add to that different A.I. algorithms to optimise and expand the translation services process.
Architecture that makes your company stronger each day, with each translated word.
Clients can take advantage of huge cost savings and new services (like generated multi-lingual content a.o.).
LSP's will operate more efficiently and gain huge workflow management advantages.
LSP's increase on their position as indispensable partners for clients, because of the complexity of the technology involved. Clients will not be able to implement anything like this themselves. In part due to the data + algorithms requirement to make this all work.
Simple workflow improvements, that companies like recently Lilt offer are a step forward, but due to their architecture can only add some efficiency gains inside an existing process, but not lift the LSP organisation to a new level taking advantage of all A.I. has to offer.
Instead, architecture that brings together the three key elements to take full advantage of the future is a much better alternative. Tolq calls this the "A.I. Backbone" which is present in all our operations. Unifying all workflows and data storage to a central, but still layered, structure. Then add to that different A.I. algorithms to optimise and expand the translation services process.
Architecture that makes your company stronger each day, with each translated word.
New Opportunities: Algorithms Galore!
What can other advances should we expect from A.I. in the near term?
LSP's can look forward to more advances for workflow optimisation and the possibility to introduce new services.
The generic engines will be one of the tools to take advantage of, but to get to the final product that clients require, LSP's that centralise their operations and data will be able to take advantage of new algorithms to offer clients new services. Some examples are shown in the diagram below. But many more will be made available as the A.I. wave increases in speed.
Value Creation Strategies for LSP's
When it comes to creating value the core strategy for LSP's should be to start combining technology with data. Even the technology giants will be envious of that combination. We expect to see huge acquisitions in that space.
In addition, combining data with algorithms can provide powerful scalable profit centers due to their nature. It's data crunching vs. human workflows.
========
Danny de Wit - CEO & Founder, Tolq
Danny de Wit founded Tolq in 2010. Danny’s drive to radically innovate the traditional world of translation was fuelled by the lack of satisfying solutions for website translation.
Danny de Wit studied Business Administration at the Erasmus University Rotterdam (Netherlands). After a career in sales, consultancy and interim management Danny’s primary focus and passion have been startups and technology.
Prior to founding Tolq Danny was involved as an entrepreneur in starting up several online businesses. Danny founded Exvo.com in 2000 en Venturez.com in 2009.
Danny’s innovative ideas, for virtualizing business organization using technology have been acknowledged by two European patents, two Dutch patents and one American patent pending. The intellectual property covers specific methods of distributing work over large populations of resources, whilst optimizing quality and efficiency of the work in real time. This technology is applied in Tolq.com.
In 2012, Tolq was a Finalist at the Launch! Conference in San Francisco and was recognised by Forbes as a startup with very promising technology describing the platform as a faster, easier and cheaper way to translate any website.
In 2014 Tolq was selected as one of the top 15 companies at The Next Web Conference and mentioned by Forbes again as one of the leading startups in Holland.
Tolq.com provides LSP's with technology architecture that puts A.I. at the core of all your LSP operations.

I'm afraid it is this sort of article that gives machine translation and AI a bad reputation among "real" translators. There are a number of red flags for me, sentences with a frothy feeling but very little identifiable content, for example:
ReplyDelete"Artificial intelligence is a wave of innovation that you have to jump on. And do so today." Who is the generic "you"? Is it me? Really me? So what do you want me to do? Where? How?
"huge cost savings and new services", "huge workflow management advantages". I'm sorry, but any use of the word "huge" in a complex area such as translation smells very much of BS bingo to me.
The "cost savings" in themselves are of course another enormous red flag, especially if they are claimed to be "huge". The author is evidently a leading voice in the choir singing the digital anthem "Degrade translators to proofreaders and pay them peanuts".
Translators? Proofreaders? Are they really needed anyway? Scanning the article, I found no reference to translators, and I only found proofreaders as an incidental item in a flow diagram.
So to me, this article merely portrays a fairy-tale world consisting of A.I. from start to finish, a world that doesn't really need humans at all.
Hi Victor,
ReplyDeleteThanks very much for pointing out that I didn't spell out the premise of the article! My mistake! The premise is that the translator is front and central in the translation process.
This is why I start with explaining that A.I. still has a number of big issues. By saying that I mean that the human translator is needed very much needed for this.
And what we do with all the A.I. stuff is try to give that human translator, or proofreader of course, what I like to call, super powers.
Use the computers to provide the things that we humans do less well (like having unlimited memory, and seeing patterns in large content quantities etc.etc.).
The 'who' in this article is LSP's not the individual translators. It's the LSP's that should use their data, combine it with technology and make sure you, the professional translator is optimally equipped to get to the optimal result for clients.
Hope that clears that up!
-- Danny