We see that Neural MT continues to build momentum and that already most people agree that generic NMT engines outperform generic phrase-based SMT engines. In fact, in recent DFKI research analysis, generic NMT even outperforms many domain-tuned Phrase-based SMT systems. Both Google and Microsoft now have an NMT foundation for many of their most actively used MT languages. However, in the professional use of MT where the MT engines are very carefully tuned and modified for a specific business purpose, PB-SMT is still the preferred model for now. It has taken many years, but today many practitioners understand the SMT technology better, and some even know how to use the various control levers available to tune an MT engine for their needs. Today, most customized PB-SMT systems involve building a series of models in addition to the basic translation memory derived translation model, to address various aspects of the automated translation process. Thus, some may also add a language model to improve target language fluency, and a re-ordering model to handle word reordering issues. Thus a source sentence could pass through several of these sub-models that address different linguistic challenges before delivering a final target language translation. In May 2017, it may be fair to say most production MT systems in the enterprise context are either PB-SMT or RBMT systems.

One of the primary criticisms of NMT today (in the professional translation world) is that NMT is very difficult to tune and adapt for the specific needs of business customers who want greater precision and accuracy in their MT system output. The difficulty, it is generally believed, is based on three things:
However, as I have described before, SYSTRAN is perhaps uniquely qualified to address this issue as they are the only MT technology developer that has deep expertise in all of the following approaches: RBMT, PB-SMT, Hybrid RBMT+SMT and now Neural MT. Deep expertise means they have developed production-ready systems using all these different methodologies. Thus, the team there may see clues that regular SMT and RBMT guys either don't see or don't understand. I recently sat down with their product management team to dig deeper into how they will enable customers to tune and adapt their Pure Neural MT systems, and they provided a clear outline of several ways by which they already address this problem today, and described several more sophisticated approaches that are in late stage development and expected to be released later this year.
The critical requirement from the business use context for NMT customization is the ability to tune a system quickly and cost-effectively, even when large volumes of in-domain data are not available.
It is useful to use the correct terminology when we discuss this, as confusion rarely leads to understanding and effective response or action. I use the term customization (in many places across various posts on this blog) as a broad term to point to the tuning process that is used to adjust an MT system for a specific and generally limited or focused business purpose, to what I think they call a "local optimum" in math. Remember in any machine learning process it is all about the data. I use the term customization to mean the general MT system optimization process which could be any of the following scenarios: Your Data + My Data, All My Data, Part of Your Data + My Data, and really, there is a very heavy SMT bias in my own use of the term customization.
SYSTRAN product management prefers to use the term "specialization" to mean any process which may perform different functions but which all consist of adapting an NMT model to a specific translation context (domain, jargon, style). From their perspective, the term, specialization better reflects the way NMT models are trained than customization because NMT models acquire new knowledge rather than being dedicated to production use in only one field. This may be a fine distinction to some, but it is significant to somebody who has been experimenting with thousands of NMT models over an extended period. The training process and its impact for NMT are quite different, and we should understand this as we go forward.
SYSTRAN provides four levels of User Dictionary capabilities in their products as described below:

The ability to do “domain specialization” of an MT system is always subject to the availability of in-domain training corpora. But often, sufficient volumes of the right in-domain corpora are not available. In this situation, apparently, NMT has a big advantage over SMT. Indeed, it is possible with NMT systems to take advantage of the mix of both generic data and in-domain data. This is done by taking an already trained generic NMT engine and “overtrain” it on the sparse in-domain data that is available. (To some extent this is possible in SMT as well, but generally, much more data is required to overpower the existent statistical pattern dominance.)
According to the team: "In this way, it is possible to obtain a system that has already learned the general (and generic) structure of the language, and which is also tuned to produce content corresponding to the specific domain. This operation is possible because we can iterate infinitely on the training process of our neural networks. That means that specializing a generic neural system is just continuing a usual training process but on a different kind of training data that are representative of the domain. This training iteration is far shorter in time than a whole training process because it is made on a smaller amount of data. It typically takes only a few hours to specialize a generic model, where it may have taken several weeks to train the generic model itself at the first time."

They also pointed out how this "over-training" process is especially good for narrow domains and what they call "hyper-specialization". "The quality produced by the specialization really depends on the relevance of the in-domain data. When we have to translate content from a very restrictive domain, such as printer manuals for example, we speak of “hyper-specialization” because a very small amount of data is needed to well represent the domain and the specialized system is rather only good for this restrictive kind of content – but really good for it."
For those who want to understand how data volumes and training iterations might impact the quality produced by the specialization, SYSTRAN provided this research paper that describes some specific experiments in some detail and shows that using more in-domain training data produces better results.


There are languages where the translation of the same source may be different given the politeness context or perhaps a different style is required. The politeness level is especially important for the Korean and Japanese (and Arabic too) languages.This feature is one of many control levers that SYSTRAN provides customers who want to tune their systems to very specific use-case requirements.
"To address this, we train our model adding metadata about the politeness context of each training example. Then, at run-time, the translation can be “driven” to produce either formal or informal translation based on the context. Currently, this context is manually set by the user, but in the near future, we could imagine including a politeness classifier to automatically set this information."
They pointed out that this is also interesting because the same concept can be applied to domain adaptation. "Indeed, we took corpora labeled with different domains (Legal, IT, News, Travel, …) and feed it to a neural network training. This way, the model not only benefits from a large volume of training examples coming from several different domains, but it also learns to adapt the translation it generates to the given context.
Again, as of today, we only use this kind of model with the user manually setting the domain he/she wants to translate, but we’re already working on integrating automatic domain detection to give this information to the model at run-time. Thus a single model could handle multiple domains."
As far as domain control is concerned, training data tagging is a step taken during the training corpus preparation process. These tags/metadata are basically annotations. They denote many kinds of information such as politeness, style, domain, category, anything that might be suitable to drive the translation in a particular direction or another. Thus, this capability could also be used to handle the multiple domains and content types that you may find on an eCommerce site like Amazon or eBay.
The annotations may be produced either by humans/annotators or via automated systems using NLP processes. However, as this is done during training preparation, this is not something that SYSTRAN clients will typically do. Then, at run-time, the model needs the same kind annotations for the source content to be translated, and again, this information may be provided either by a user action (e.g: the user selects a domain) or by an automated system (automatic domain detection).
 There is some further technical description on Domain Control in this paper.
There is some further technical description on Domain Control in this paper.
The following graphic puts the available adaptation approaches in context and shows how these different approaches vary in terms of effort/time investment and what impact the different strategies may have on the output quality. Using multiple approaches at the same time also adds further power and control to the overall adaptation scenario. The methods of tuning shown here are not incremental or sequential. They can all be used together as needed and as is possible. For those who have been following the discussion with Lilt on their "MT evaluation" study, can now perhaps understand why an instant BLEU snapshot based evaluation is somewhat pointless and meaningless. Judging and ranking MT systems comparatively on BLEU scores like Lilt has done, without using tuning tools properly, is misleading and even quite rude. Clients who can adapt their MT systems to their specific needs and requirements will always do so, and will often use all the controls at their disposal. SYSTRAN makes several controls available in addition to the full (all my data + all your data training) customization described earlier. I hope that we will soon start hearing from clients and partners who have learned to operate and use these means of control and are willing to share their experience so that our MT initiatives continue to gain momentum.


One of the primary criticisms of NMT today (in the professional translation world) is that NMT is very difficult to tune and adapt for the specific needs of business customers who want greater precision and accuracy in their MT system output. The difficulty, it is generally believed, is based on three things:
- The amount of time taken to tune and customize an NMT system,
- The mysteriousness of the hidden layers that make it difficult to determine what might fix specific kinds of error patterns,
- The sheer amount/cost of computing resources needed in addition to the actual wall time.
However, as I have described before, SYSTRAN is perhaps uniquely qualified to address this issue as they are the only MT technology developer that has deep expertise in all of the following approaches: RBMT, PB-SMT, Hybrid RBMT+SMT and now Neural MT. Deep expertise means they have developed production-ready systems using all these different methodologies. Thus, the team there may see clues that regular SMT and RBMT guys either don't see or don't understand. I recently sat down with their product management team to dig deeper into how they will enable customers to tune and adapt their Pure Neural MT systems, and they provided a clear outline of several ways by which they already address this problem today, and described several more sophisticated approaches that are in late stage development and expected to be released later this year.
The critical requirement from the business use context for NMT customization is the ability to tune a system quickly and cost-effectively, even when large volumes of in-domain data are not available.
What is meant by Customization and Specialization?
It is useful to use the correct terminology when we discuss this, as confusion rarely leads to understanding and effective response or action. I use the term customization (in many places across various posts on this blog) as a broad term to point to the tuning process that is used to adjust an MT system for a specific and generally limited or focused business purpose, to what I think they call a "local optimum" in math. Remember in any machine learning process it is all about the data. I use the term customization to mean the general MT system optimization process which could be any of the following scenarios: Your Data + My Data, All My Data, Part of Your Data + My Data, and really, there is a very heavy SMT bias in my own use of the term customization.
SYSTRAN product management prefers to use the term "specialization" to mean any process which may perform different functions but which all consist of adapting an NMT model to a specific translation context (domain, jargon, style). From their perspective, the term, specialization better reflects the way NMT models are trained than customization because NMT models acquire new knowledge rather than being dedicated to production use in only one field. This may be a fine distinction to some, but it is significant to somebody who has been experimenting with thousands of NMT models over an extended period. The training process and its impact for NMT are quite different, and we should understand this as we go forward.
The Means of NMT Specialization - User Dictionaries
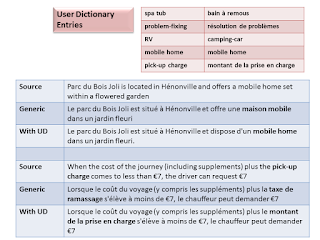
A user dictionary (UD) is a set of source language expressions associated with specific target language expressions, optionally with Part Of Speech (POS) information. This is sometimes called a glossary in other systems. User dictionaries are used to ensure a specific translation is used on some specific parts of a source sentence within a given MT system. This feature allows end-users to integrate their own preferred terminology for critical terms. In SYSTRAN products, UDs have been historically available and used extensively for their Rule-Based Systems. User Dictionary capabilities are also implemented in SYSTRAN SMT and Hybrid (SPE - Statistical Post-Editing) systems.SYSTRAN provides four levels of User Dictionary capabilities in their products as described below:
- Level 1: Basic Pattern Matching: The translation source input is simply matched against the exact source dictionary entries and the preferred translation target string is output.
- Level 2: Level 1 + Homograph Disambiguation: Sometimes, a source word may have different part-of-speech (POS) associations. A Level 2 UD entry is selected according to its POS in the translation input, and then the right translation is provided. An example:
- “lead” as a noun: Gold is heavier than lead > L'or est plus lourd que le plomb
- “lead” as a verb: He will lead the meeting > Il dirigera la reunion
- Level 3: Morphology: A single base form from an UD entry may match different inflected forms of the same term, thus the translation is produced by the proper inflection of the target form of the UD entry according to matched POS and grammatical categories.
- Level 4: Dependence: This allows a user to define rules to translate a matched entry depending on other conditionally matched entries.

The Means of NMT Specialization - Domain Specialization & Hyper-Specialization
The ability to do “domain specialization” of an MT system is always subject to the availability of in-domain training corpora. But often, sufficient volumes of the right in-domain corpora are not available. In this situation, apparently, NMT has a big advantage over SMT. Indeed, it is possible with NMT systems to take advantage of the mix of both generic data and in-domain data. This is done by taking an already trained generic NMT engine and “overtrain” it on the sparse in-domain data that is available. (To some extent this is possible in SMT as well, but generally, much more data is required to overpower the existent statistical pattern dominance.)
According to the team: "In this way, it is possible to obtain a system that has already learned the general (and generic) structure of the language, and which is also tuned to produce content corresponding to the specific domain. This operation is possible because we can iterate infinitely on the training process of our neural networks. That means that specializing a generic neural system is just continuing a usual training process but on a different kind of training data that are representative of the domain. This training iteration is far shorter in time than a whole training process because it is made on a smaller amount of data. It typically takes only a few hours to specialize a generic model, where it may have taken several weeks to train the generic model itself at the first time."

They also pointed out how this "over-training" process is especially good for narrow domains and what they call "hyper-specialization". "The quality produced by the specialization really depends on the relevance of the in-domain data. When we have to translate content from a very restrictive domain, such as printer manuals for example, we speak of “hyper-specialization” because a very small amount of data is needed to well represent the domain and the specialized system is rather only good for this restrictive kind of content – but really good for it."
For those who want to understand how data volumes and training iterations might impact the quality produced by the specialization, SYSTRAN provided this research paper that describes some specific experiments in some detail and shows that using more in-domain training data produces better results.


The Means of NMT Specialization - Domain Control
This was an interesting feature and use-case that they presented to me to handle special kinds of linguistic problems. Their existing tuning capabilities are positioned to be able to be extended to handle automated domain identification and special style and politeness-level issues in some languages. Domain Control is an approach that allows a single training and model to be developed that can be used to handle multiple domains, with some examples given below.There are languages where the translation of the same source may be different given the politeness context or perhaps a different style is required. The politeness level is especially important for the Korean and Japanese (and Arabic too) languages.This feature is one of many control levers that SYSTRAN provides customers who want to tune their systems to very specific use-case requirements.
"To address this, we train our model adding metadata about the politeness context of each training example. Then, at run-time, the translation can be “driven” to produce either formal or informal translation based on the context. Currently, this context is manually set by the user, but in the near future, we could imagine including a politeness classifier to automatically set this information."
They pointed out that this is also interesting because the same concept can be applied to domain adaptation. "Indeed, we took corpora labeled with different domains (Legal, IT, News, Travel, …) and feed it to a neural network training. This way, the model not only benefits from a large volume of training examples coming from several different domains, but it also learns to adapt the translation it generates to the given context.
Again, as of today, we only use this kind of model with the user manually setting the domain he/she wants to translate, but we’re already working on integrating automatic domain detection to give this information to the model at run-time. Thus a single model could handle multiple domains."
As far as domain control is concerned, training data tagging is a step taken during the training corpus preparation process. These tags/metadata are basically annotations. They denote many kinds of information such as politeness, style, domain, category, anything that might be suitable to drive the translation in a particular direction or another. Thus, this capability could also be used to handle the multiple domains and content types that you may find on an eCommerce site like Amazon or eBay.
The annotations may be produced either by humans/annotators or via automated systems using NLP processes. However, as this is done during training preparation, this is not something that SYSTRAN clients will typically do. Then, at run-time, the model needs the same kind annotations for the source content to be translated, and again, this information may be provided either by a user action (e.g: the user selects a domain) or by an automated system (automatic domain detection).

The following graphic puts the available adaptation approaches in context and shows how these different approaches vary in terms of effort/time investment and what impact the different strategies may have on the output quality. Using multiple approaches at the same time also adds further power and control to the overall adaptation scenario. The methods of tuning shown here are not incremental or sequential. They can all be used together as needed and as is possible. For those who have been following the discussion with Lilt on their "MT evaluation" study, can now perhaps understand why an instant BLEU snapshot based evaluation is somewhat pointless and meaningless. Judging and ranking MT systems comparatively on BLEU scores like Lilt has done, without using tuning tools properly, is misleading and even quite rude. Clients who can adapt their MT systems to their specific needs and requirements will always do so, and will often use all the controls at their disposal. SYSTRAN makes several controls available in addition to the full (all my data + all your data training) customization described earlier. I hope that we will soon start hearing from clients and partners who have learned to operate and use these means of control and are willing to share their experience so that our MT initiatives continue to gain momentum.


An excellent summary of this subject, Kirti. You pick up bits & pieces on the OpenNMT forum which is generously led by the Systran people but this is the first time I have seen things set out so clearly. I've personally been adding a few things on the input side of the equation with the result that my NMT is not quite so pure but some simple issues are resolved.
ReplyDeleteTerence