This is a guest post by Roberto Navigli of BabelNet, a relatively new "big language data" initiative that is currently a lexical-semantic research and analysis tool, that can do disambiguation and has been characterized by several experts as a next-generation dictionary. It is a tool where "concepts" are linked to the words used to express them. BabelNet can also function as a semantics-savvy, disambiguation capable MT tool. The use possibilities are still being explored and could expand as grammar related big data is linked to this foundation. As Roberto says:"We are using the income from our current customers to enrich BabelNet with new lexical-semantic coverage, including translations and definitions. In terms of algorithms, the next step is multilingual semantic parsing, which means moving from associating meanings with words or multiword expressions to associating meanings with entire sentences in arbitrary languages. This new step is currently funded by the European Research Council (ERC). The Babelscape startup already has several customers, among them, are Lexis Nexis, Monrif (a national Italian newspaper publisher), XTM (computer-assisted translation), and several European and national government agencies.
While the initial intent of the project was broader than being a next-generation dictionary, attention and interest from the Oxford UP have steered this initiative more in this direction.
I expect we will see many new kinds of language research and analysis tools become available in the near future, as we begin to realize that all the masses of linguistic data that we have access to that can be used for many different linguistically focused projects and purposes. The examples presented in the article below are interesting, and the Babelscape referenced tools mentioned here are easy to access and experiment with. I would imagine that these kinds of tools and built-in capabilities would be an essential element of next-generation translation tools where this kind of a super-dictionary would be combined and connected with MT, Translation Memory, Grammar checkers and other linguistic tools that can be leveraged for production translation work.
While the initial intent of the project was broader than being a next-generation dictionary, attention and interest from the Oxford UP have steered this initiative more in this direction.
I expect we will see many new kinds of language research and analysis tools become available in the near future, as we begin to realize that all the masses of linguistic data that we have access to that can be used for many different linguistically focused projects and purposes. The examples presented in the article below are interesting, and the Babelscape referenced tools mentioned here are easy to access and experiment with. I would imagine that these kinds of tools and built-in capabilities would be an essential element of next-generation translation tools where this kind of a super-dictionary would be combined and connected with MT, Translation Memory, Grammar checkers and other linguistic tools that can be leveraged for production translation work.
=========

BabelNet: a driver towards a society without language barriers?
In 2014 the Crimean war broke out and is currently going on, but no national media is talking about it anymore. So now Rachel has been trying for 1 hour to find information about the current situation but she can only find articles written in Cyrillic that she is not able to understand. She is about to give up when her sister says: “Have you tried to use BabelNet and its related technology? It is the best way to understand a text written in a language that you do not know!”, so she tries and gets the information from the article.
The widest multilingual semantic network
We are talking about the largest multilingual semantic network and encyclopedic dictionary, created by Roberto Navigli, founder and CTO of Babelscape and full professor at the Department of Computer Science at the Sapienza University of Rome, born as a merger of two different resources, WordNet and Wikipedia. However, what makes BabelNet special is not the specific resources used, but how they interconnect with each other. In fact, it is not the first system to exploit Wikipedia or WordNet, but it is the first one to merge them, taking encyclopedic entries from Wikipedia and lexicographic entries from WordNet. Thus BabelNet is a combo of resources that people usually access separately.
Furthermore, one of the main features of BabelNet is its versatility, since its knowledge enables to design applications to analyze text in multiple languages and extract various types of information. For example, Babeltex, a concept and entity extraction system based on BabelNet, is able to spot entities and extract terms and their meaning from sentences in a text (an article, a tweet, and any other type of phrase) and, as a result, Rachel is able to understand what the article is talking about. However, she realizes that Babelfy is not a translator, but a tool to identify concepts and entities within text and get their meanings in different languages: when Rachel uses it, the network spots the entities in the article, it finds the multiple definitions of a word and matches their meaning with an image and their translations in other languages, so in this way she can get the content itself of the text. In addition, Babelfy shows the key concepts related to any entities.
Let me show you two examples of how Babelfy works. First, look at the following statement. “Lebron and Kyrie have played together in Cleveland”.
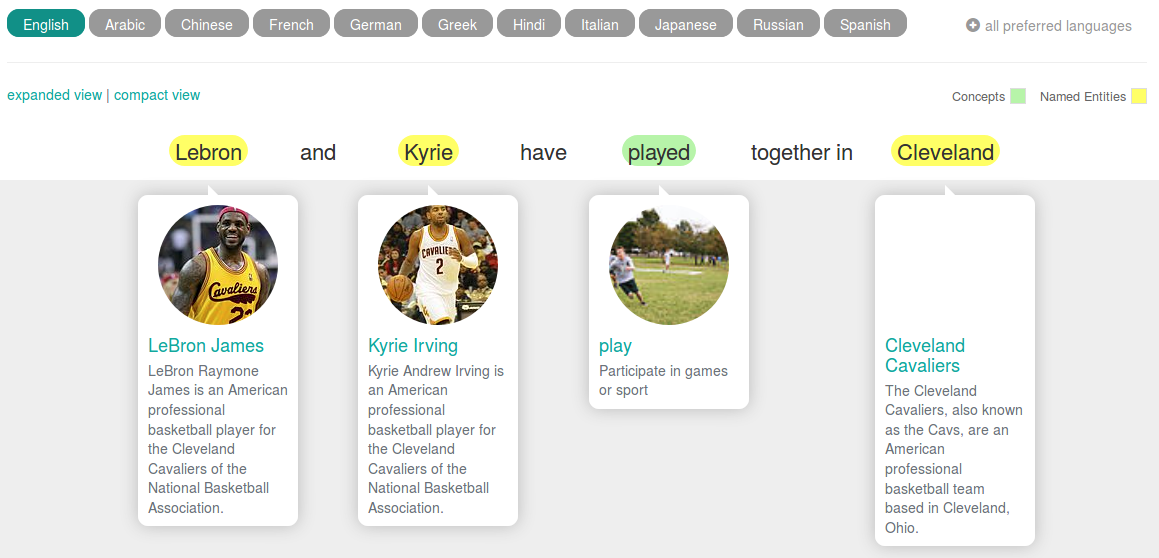
In this case Babelfy has to disambiguate a text written in English and to explain it in the same language: its task is to recognize concepts (highlighted in green) and named entities (highlighted in yellow) and to match the proper meaning to every concept according to the sentence; finally it provides an information sheet based on the BabelNet’s knowledge for any entity and concept. Thus in the previous example, Babelfy works first as a disambiguator able to understand that “Cleveland” means “the basketball team of the city” and not the city itself, and then as an encyclopedia, by providing information sheets about the various entities and concepts.
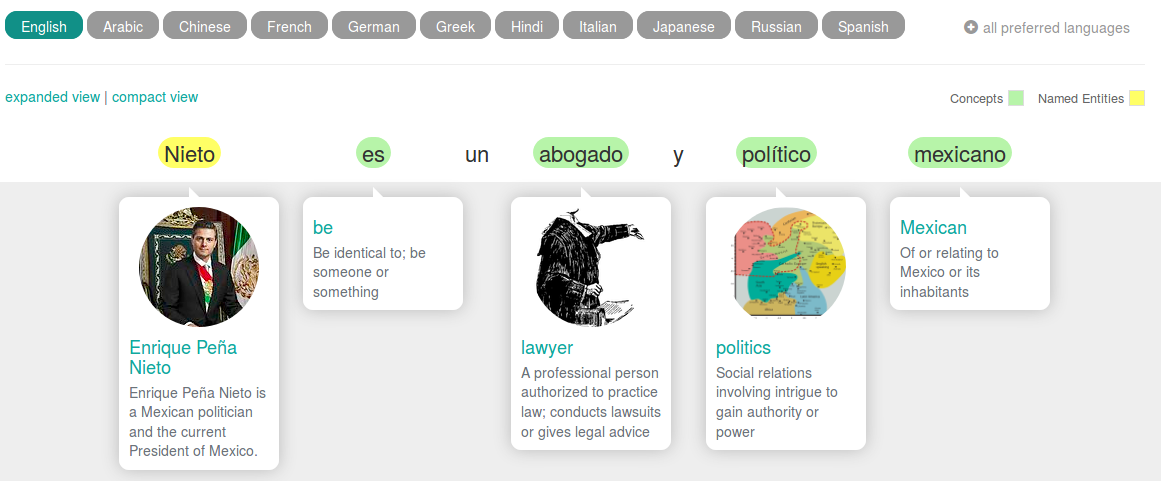
The second example shows how Babelfy faces Rachel’s problem. We have a text written in Spanish. Babelfy recognizes the concepts (es, abogado, político, mexicano) and the named entity (Nieto) and provides the information sheets in the selected language (English). Babelfy can, therefore, help you understand a text written in a language you do not speak.
This can be repeated in hundreds of languages: no one can guarantee a linguistic coverage as wide as Navigli’s company, currently about 271 languages, including Arabic, Latin, Creole, and Cherokee. That is why BabelNet won the META Prize in 2015, motivated by the jury “for groundbreaking work in overcoming language barriers through a multilingual lexicalized semantic network and ontology making use of heterogeneous data sources. The resulting encyclopedic dictionary provides concepts and named entities lexicalized in many languages, enriched with semantic relations”.

Roberto Navigli awarded the META Prize (Photo of the META-NET 2015 prize ceremony in Riga, Latvia).
Make your life better: have fun with knowledge, get insights for your business
But, we have to be practical. We know what this network does, but can it improve our life? The answer is “of course!”, whether you are a computer scientist or just a user. If you are a user, you can follow BabelNet’s slogan, “Search, translate, learn!”, and enjoy your time by exploring the network and dictionary. People can have fun by discovering the interconnection among the words, playing with the knowledge. But BabelNet is not just about this: in her article “"Redefining the modern dictionary", Katy Steinmetz, a journalist of Time Magazine, states that BabelNet is about to revolutionize the current dictionaries and to take them to the next level. According to Steinmetz, the merit of BabelNet is “going far beyond the ‘what’s that word mean’ use case” because the multilingual network has been organized using the meaning of the words, not their spelling and the useless alphabetical order as the print dictionaries do, and in addition it offers a wider language coverage and an illustration for any term. Why should you use a common dictionary when you have another with any entry matched to a picture and definitions in multiple languages? Thus BabelNet is a pioneer at the turning point from dictionaries to a semantic network structure with labeled relations, pictures, and multilingual entries, and makes gaining knowledge and information easier for users.
Computer scientists, on the other hand, can exploit BabelNet to disambiguate a written text in one of the hundreds of covered languages. For example, BabelNet can be used to build a term extractor able to analyze tweets or any social media chat about the products of a company and spot the entities with the matched picture and concepts. In this way, the marketing manager can understand what a text is talking about regardless of language and can get insights to improve the business activities.
A revolution in progress
Even though its quality is already very high, the current BabelNet should be considered as “a starting point” for much richer versions to come of the multilingual network, because new lexical knowledge is continuously added with daily updates (for example, when a new state president is elected this fact will be integrated into BabelNet as soon as Wikipedia is updated). The focus on upgrading technology and linguistic level comes from the background of Roberto Navigli (winner of the Prominent Paper Award 2017 from Artificial Intelligence, the most prestigious journal in the field of AI), who has put together a motivated operational team.
After the starting combination between Wikipedia and WordNet, new and different resources (Open Multilingual WordNet, Wikidata, Wiktionary, OmegaWiki, ItalWordNet, Open Dutch WordNet, FrameNet, Wikiquote, VerbNet, Microsoft Terminology, GeoNames, WoNeF, ImageNet) have been added to the next versions in order to provide more synonyms and meanings and to increase the available knowledge. The BabelNet team is not going to stop innovating, so who knows which other usages BabelNet could offer in the future: the revolution of our life by BabelNet has just begun. Should we start thinking about a society without language barriers?

{kind=link}
No comments:
Post a Comment